Archival Descriptive Metadata & JSON¶
Many cultural organizations, such as the US National Archives, provide a read-write web API (Application Programming Interface) for accessing catalog content from a program. Typically, these catalogs when queried through API calls, return JSON-formated data. This data can be viewed through a JSON Browser or through regular browsers (sometimes requiring a JSON extension). An online viewer we have used is: jsoneditoronline.org
NARA's Hierarchical Catalog Structure:¶
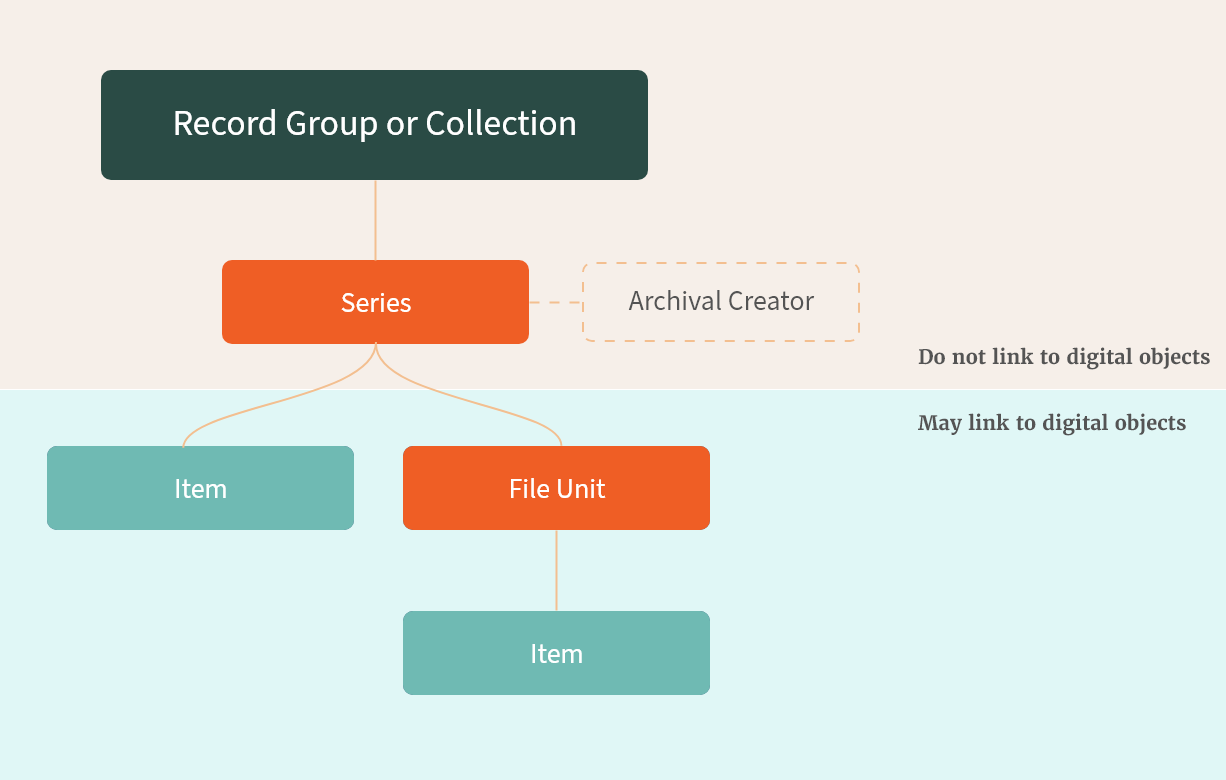
Record groups and collections are the highest level of archival description. Record groups most often contain accessioned records from federal agencies. Collections are generally made up of non-federal records that were donated to NARA, usually from presidential administrations.
Beneath the record group or collection is the series. A series is a group of records that are related as the result of being created, received, or used in the course of the same activity. The series is the descriptive level that is connected to the archival creator - the person or organization who created and/or maintained the records.
And beneath the series are file units or items. File units contain a more specific collection of related records within a series. A file unit often contains multiple discrete records, for example a grouping of memos. File units are always contained by series, while items can be contained by either series or file units. An item often reflects a specific record, for example a single memo. Both file units and items can contain digital objects, such as digitized pages produced from analog holdings.
The National Archives Catalog API contains all:¶
- Archival description metadata
- Authority record (persons, organizations, geographic references, topical subjects, and specific records types) metadata
- Digital object metadata (including technical metadata)
- Public contributions to the catalog (like tags and transcriptions)
- Metadata for crawled web pages of archives.gov and presidential libraries
- Some metadata for user accounts

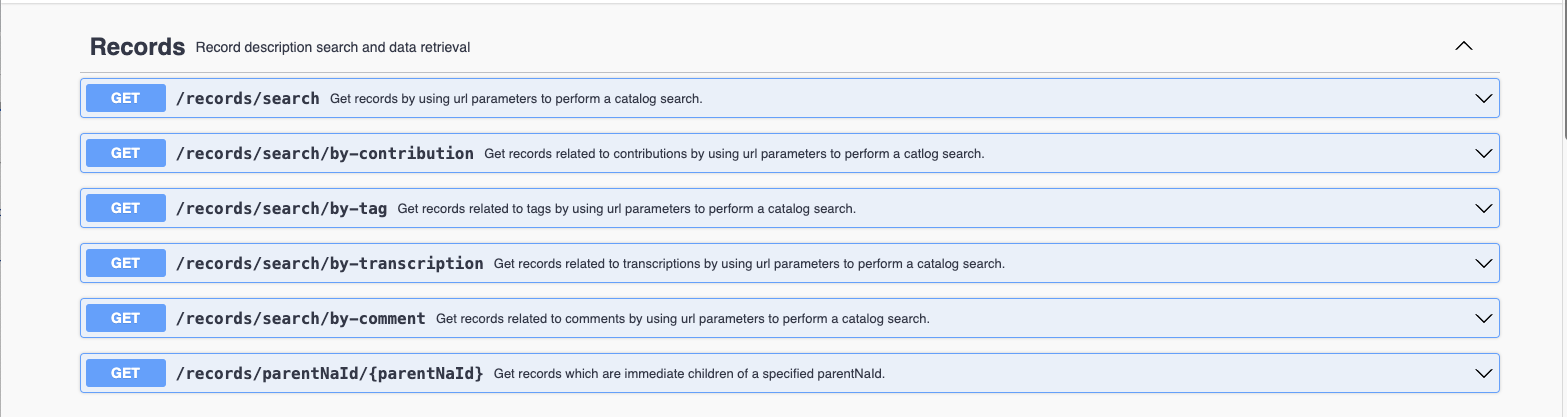
Examples of API calls:
- https://catalog.archives.gov/api/v2/records/search?q=constitution
- https://catalog.archives.gov/api/v2/records/parentNaId/537?parentNaid=537"
See:
Let's learn more about JSON first:
JSON:¶
- is ("Pronounced /ˈdʒeɪ.sən/, as in 'Jason and The Argonauts'")
- is the JavaScript Object Notation (JSON) Data Interchange Format, December 2017
- is a very popular data format for APIs (Aplication Programming Interfaces allow two applications to talk to each other)
- is stored directly in NoSQL based databases like MongoDB
More details:¶
- an international ISO standard (ISO/IEC 21778:2017) of which RFC 8259 is the current version of the Internet Standard STD 90
- a lightweight, text-based, language-independent data interchange format
- a text format for the serialization of structured data
- a subset of JavaScript (JS is a programming language used both on the client-side and server-side that allows you to make web pages interactive)
JSON can represent:¶
- data as a name:value pair, consisting of a field name (in double quotes), followed by a colon, followed by a value
- a list of name:value pairs (separated by commas), where values:
- are one of four primitive types: strings, numbers, booleans, and null
- can also be one of two structured types: objects and arrays
- An ARRAY (which uses square brackets) is an ordered sequence of zero or more values
- An OBJECT (which uses curly brackets) is an unordered collection of zero of more name/value pairs
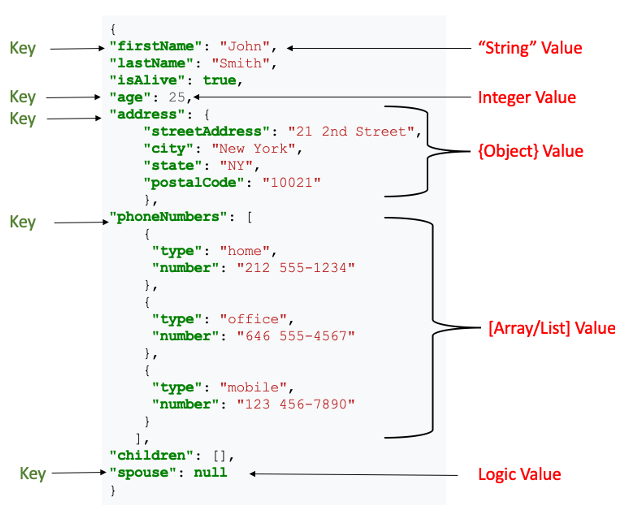
The following example shows a possible JSON object representation describing a person.
In other words JSON can lend itself to modeling complex hierarchical nested data.
The JSON data format is very similar to the Python language Dictionary structure¶
Because Dictionaries in the Python programming languange are one of the four principal collection types (List, Tuple, Set, and Dictionary) and are used to store information in key:value pairs, they are a natural way of expressing and manipulating JSON content.
Python code for creating and printing your first dictionary:
firstdict = {
"filename": "readme.txt",
"year": 2021,
"pagecount": 12
}
print( firstdict )
{'filename': 'readme.txt', 'year': 2021, 'pagecount': 12}
Printing a particular Dictionary value:¶
- Print the "year" value of the dictionary (using the square bracket notation):
print( firstdict[ "year" ])
2021
Python code for creating and printing your second dictionary:
seconddict = {
"filename": "readme.txt",
"year": 2021,
"pagecount": 12,
"year": 2000
}
print( seconddict )
{'filename': 'readme.txt', 'year': 2000, 'pagecount': 12}
The Second Dictionary example shows that in Python (as of version 3.7), dictionaries are ordered (items have a defined order, and that order will not change), and do not allow duplicates (duplicate values will overwite existing values).
The four Python collection data types are:
- List is a collection which is ordered and changeable. Allows duplicate members. Is indexed by an integer index.
- e.g.: list1 = ("one", "two", "three")
- Tuple is a collection which is ordered and unchangeable. Allows duplicate members.
- e.g.: tuple1 = ("one", "two", "three")
- Set is a collection which is unordered and unindexed. No duplicate members.
- e.g.: set1 = {"one", "two", "three"}
- Dictionary is a collection which is now ordered and changeable. No duplicate members. Is indexed by a key (as opposed to List).
- e.g.: dict1 = ("one":1, "two":2, "three":3)