A Data-Driven Approach to Reparative Description at the University of Chicago¶
Designed by Ashley Gosselar, 2022

Table of Contents¶
Introduction¶
Reparative description of collections is a burgeoning element of diversity, equity, and inclusion efforts at cultural heritage institutions. Broadly speaking, reparative description aims to remediate or contextualize metadata about collections that exclude, silence, harm, or mischaracterize people. Reparative description practices strive to be accurate, inclusive, culturally competent, and respectful. Reparative description work can take may forms as illustrated in the graphic below from this presentation about reparative description given by the Native American Archives Section of the Society of American Archivists in 2021.
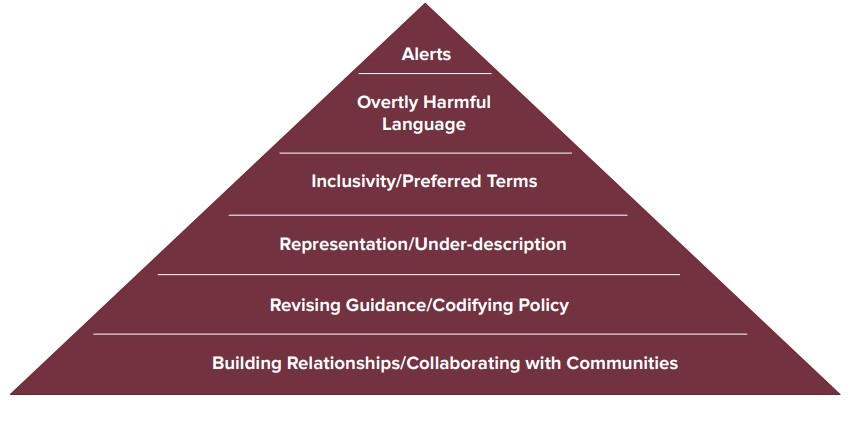
For many years, archivists at the University of Chicago Library’s Hanna Holborn Gray Special Collections Research Center have made inroads in the “Representation/Under-description” tier of the above illustration through a concerted effort to thoughtfully process and make accessible collections that represent diverse groups of people and organizations. However, due in part to severe staffing shortages, the Center has not invested significant time and resources in other tiers of the illustration. The Center maintains over 1600 online finding aids – a daunting amount of legacy metadata to review and remediate.
To meet this challenge, I proposed a data-driven approach to identify and prioritize finding aids for reparative description. While the work of editing a finding aid through a reparative description lens is not something that can be automated or sensitively done without careful, time-intensive attention by a human being, this project demonstrates that computational thinking can be applied to the planning stages of reparative description work. I tackled the question of “where do we begin?” by treating the Center’s 1600+ finding aids as data that can be harvested, transformed, and analyzed with computational methodologies.
I am not the first archivist to try this. By searching the Internet, archival literature, and GitHub, and by informally surveying 75 members of a reparative description Slack channel for processing archivists, I arrived at the following list of archival institutions and archivists who are using computer script to audit their finding aids for potentially biased and harmful language:
- Princeton University Library, Special Collections. Code by Kelly Bolding.
- Getty Research Institute’s Anti-Racist Description Working Group. Code by Laura Schroffel.
- University of Pittsburgh Library, Archives and Special Collections. Code by Kayla Heslin.
- Duke University Rubenstein Library. Code by Miriam Shams-Rainey.
- Harvard University Houghton Library. Code by Vernica Downey.
- Yale University Library. Code by Alicia Detelich Boersig.
- University of California, Riverside. Code by Noah Geraci.
Factoring in limitations on my time, a lack of technical support, and my rudimentary understanding of XQuery, XSLT, regular expressions, and Python , I decided to not reinvent the wheel and write my own script. From this list, I chose Laura Schroffel’s Python script, “XML-Term-Detective” as my tool for scraping data from UChicago’s finding aids. I chose XML-Term-Detective because it utilizes a GUI and does not require a full understanding of Python to operate. I am grateful to Laura for graciously permitting me to use this code and publicly discuss my experience using it.
This project builds upon the scripting work established by others to include other data curation steps. Thanks to knowledge gained in the University of Maryland iSchool’s Digital Curation for Information Professionals certificate program, I used a suite of data curation tools to clean, enhance, visualize, and analyze my data. In so doing, I was able to learn not just when and where biased or harmful language may occur in UChicago’s finding aids, but the scale and scope of the problem and which finding aids require the most remediation.
The following is an explication of my methodology and the inferences and recommendations I drew from the data. It is written with two audiences in mind: my colleagues at the University of Chicago who will use this report to begin the slow but important work of reparative description of our finding aids, and a more general audience of archivists with basic technology skills embarking on reparative description work at their own institutions. By utilizing the format of a Jupytr Notebook, I hope to make this project more easily reproducible and repurpose-able for others.
For beginners seeking a basic grasp of XQuery and XSLT, I recommend Library Juice Academy’s course Transforming and Querying XML with XSLT and XQuery. For an introduction to Python within a humanistic context, I recommend Melanie Walsh’s Introduction to Cultural Analytics & Python. For a crash course in regular expressions, command line, and Git, I recommend Library Carpentry workshops. I used each of these courses to expand my technical skillset and prepare for this project.
Methodology¶
Gathering the Data¶
The Lexicon¶
XML-Term-Detective finds and counts terms from a csv list across a directory of xml files. UChicago’s finding aids are encoded in EAD (an XML standard) and live in a directory accessible to staff (in other words, I did not need to export XML finding aids out of a system like ArchivesSpace and into a directory). Laura Schroffel helpfully shared the Getty Research Institute’s csv list of terms, which they call “the lexicon.” (Yale also happens to be using the Getty's lexicon to develop metadata action plans across their cultural heritage collections.)
I used the Getty’s lexicon of terms as my starting point. I came to think of the words in the lexicon as “red flag terms.” A word might be outright offensive (such as a racial slur), or it might indicate that the subject matter of a finding aid merits review to ensure that we are describing a collection in an inclusive and culturally competent way.
There are several categories of terms in the lexicon:
- Terms of aggrandizement (which we especially want to root out of Biographical/Historical notes)
- Ableist language
- Terms about race and ethnicity
- Language about citizenship (“alien” to refer to noncitizens or undocumented immigrants)
- Words related to class
- Words about incarceration or forced removal
- Terms that might tip us off to documentation of colonialism, genocide, or slavery. These finding aids could be reviewed for erasure or misrepresentation of Native Americans and enslaved people, for euphemistic language describing racial violence, or for description that glosses over relationships of power (for instance, if a white person is described as a planter or plantation owner with no allusion to the fact that they enslaved people on said plantation).
- Sexist language (women described as girls or only as “Mrs. Husband’s Name”)
I edited the Getty lexicon in several ways. I removed some terms that I knew would create “noise” in the data. For instance, I removed the word “great” because the University of Chicago archives holds records of its “Great Books” program that would clutter my dataset. I also removed words that had zero hits in our online finding aids database (words like “midlife” and “codger.”).
I also added many words (see Added Terms below). XML-Term-Detective does not automatically look for variations of a word such as the pluralization, so I added those. I included additional terms of aggrandizement found in Kelly Bolding’s list for Princeton University. I added words that occurred to me as I read the University of North Carolina, Chapel Hill’s Guide to Conscious Editing, and selected additional words from Kayla Heslin’s Legacy Description Audit script for the University of Pittsburgh, which pulls from hatebase.org, a repository of multilingual hate speech. I added terms suggested by colleagues based on their knowledge of our collections.
Added Terms¶
- accomplished
- alien
- aliens
- aptitude
- authority
- coolie
- coolies
- creative
- creativity
- deformed
- deformity
- distinctive
- dynamic
- dynamism
- elite
- enfeebled
- girl
- idiot
- impressive
- incisive
- Indians
- instrumental
- interned
- internment
- invaluable
- morons
- negros
- negroes
- nigger
- niggers
- notable
- pioneer
- pioneers
- pioneered
- pioneering
- plantation
- planter
- planters
- relocate
- relocated
- reputation
- reservation
- squaw
- riot
- slaves
- tremendous
Imperfections in the Lexicon¶
XML-Term-Detective does not search for phrases. Therefore, some language will be overlooked; for instance, aggrandizing language such as “father of,” “man of letters,” and “leading role.” Duke University’s script appears to handle phrases, so it may be worth taking a second run at our finding aids with this script.
Many slurs and derogatory language are missing. There is some hate speech in the list, but it is not comprehensive. The University of Pittsburgh script searches for a longer list of slurs by pulling from hatebase.org. This is another script worth trying in the future. The slurs that I did include are listed because examples popped up when I searched for them in our finding aids database. A lot of the slurs I included in the lexicon appear in old titles (for instance, in published song titles held in our jazz collections).
LGBTQ+ terms do not appear in the lexicon. The original Getty lexicon does not include any LGBTQ+ terms, and the University of Pittsburgh’s script only uses a couple. Duke University’s lexicon does include some LGBTQ+ terms, but not many. Through discussion with UChicago colleagues, I decided that a review of LGBTQ+ collections merited a different approach to reparative description planning. LGBTQ+ vocabulary is vast and evolving, and a lot of derogatory terms have been reclaimed by some members of the LGBTQ+ community. Therefore, flagging LGBTQ+ terms via XML-Term-Detective may not be a useful activity. Additionally, words like “dyke” result in a lot of noise in the data because it is fairly common as a surname or as a part of a surname. We need to be very careful to not mis-gender or mis-identify someone’s sexuality when the historic record does not clearly spell out how a person identified themselves. (we similarly need to tread lightly around descriptions of a person’s race.) In this context, XML-Term-Detective feels like the adage “if your only tool is a hammer then every problem looks like a nail.” A better approach to reparative description of LGBTQ-related collections would be to follow models such as the Metadata Best Practices for Trans and Gender Diverse Resources by the Trans Metadata Collective, and the Digital Transgender Archive which uses the Homosaurus. We also need to ensure that LGBTQ+ collections in our care have finding aids, and that they are not under-described. This is important work, and a job that can’t easily be jump-started with a tool like XML-Term-Detective.
Bias Bias Bias! ⚠️¶
Finally, I acknowledge that any lexicon, including my own, may be fraught with unconscious bias. Any time we describe or categorize human beings we risk the pitfalls of our own narrow worldview and understanding of the human experience. Computer programs are made by humans and subject to bias. Tools like XML-Term-Detective are not magic bullets for reparative description. I am using XML-Term-Detective as a starting point only. Reparative description is complex, iterative work that cannot be accomplished with “Find and Replace.” Rather, it necessitates slowing down, listening carefully, and thinking critically. My hope for this project is that it helps UChicago and other institutions to begin this work in an efficient way and chart a logical path through a complex landscape.
Using XML-Term-Detective¶
Now let’s roll up our sleeves and get to work! To use XML-Term-Detective, you need to install Python on your computer. I followed Melanie Walsh’s instructions for installing Anaconda and launching JupyterLab. You also need to download XML-Term-Detective from GitHub.
Next, make sure you know where your lexicon is saved to your computer and that it is saved as a csv file.
Then, make sure that your finding aid xml files are saved to a directory that XML-Term-Detective can access.
After launching JupyterLab from Anaconda, open a terminal in JupyterLab.
In the terminal, type cd XML-Term-Detective
Then type python XMLTermDetective.py into the terminal.

A GUI window opens!

Follow Laura Schroffel’s instructions in the ReadMe file on GitHub for using XML-Term-Detective.
XML-Term-Detective produces two output files (csv format). One output lists the xml files in which red flag terms were located, the particular term that was located, the line number in the xml in which the term was located, and the text of that line. The other output shows how many times each red flag term was found in an xml file (including zero). See Appendix to download my two output files.
Cleaning and Enhancing the Data¶
First, a disclaimer. I am a novice data wrangler. Someone with more data science experience would likely have savvier ways of cleaning and transforming this data.
I looked at the data first in Excel. If a term had zero hits in the “count” output, I removed it from the lexicon and ran it back through XML-Term-Detective. Nine terms from my lexicon were removed.
I then uploaded the full output csv into a cloud-based data wrangling tool called Trifacta. As of this writing, you can get a 30-day free trial of Trifacta, and if you are a student you can extend that free trial for a year.
Instructions for importing data into Trifacta.
In Trifacta, I sorted the data alphabetically by term (the WORD column). Using the histogram at the top of the “word” column, I looked at which terms were found the most, and started with those. (I eventually went row by row through the entire output.)

I deleted rows that were “noise” in the data. The following functions proved especially useful in my “recipe”:
- This function will delete rows that find specified terms in two columns:
(Note: This function is case-sensitive so you need to search for uppercase and lowercase spellings.)
Delete rows where MATCHES([{column name}], 'term or phrase|another term or phrase|another term or phrase', false) && MATCHES([{column name}], 'term', false)
For example, XML-Term-Detective found many innocent words that include “psycho” such as “psychology,” “psychiatrist,” and “psychoanalyst.” I wanted to remove this noise from my data. So, I wrote my function this way:
Delete rows where MATCHES([{LINE TEXT}], 'psychol|psychi|psychoa', false) && MATCHES([{WORD}], 'psycho', false)
- Certain terms of aggrandizement, such as "notable" and "popular" create noise in the data. I am most concerned about terms of aggrandizement that appear in the Biog/Hist and Scope notes. I deleted any results where the line text contains unittitle or subject tags as this indicates a folder heading, related resource, or subject heading containing the term, rather than a paragraph tag within a Biog/Hist or Scope Note containing the term.
Delete rows where MATCHES([{LINE TEXT}],, false) && (MATCHES([{WORD}], 'term', false) || MATCHES([{WORD}], 'another term', false))
For example,
Delete rows where MATCHES([{LINE TEXT}],, false) && (MATCHES([{WORD}], 'notable', false) || MATCHES([{WORD}], 'popular', false))
- If a collection was creating noise in the data, I eliminated it this way:
Delete rows where MATCHES([FILE], 'filename’, false) && MATCHES([{WORD}], 'term', false)
For example, I knew that “Indian” in the Chandrasekhar papers referred to people from South Asia, not Native Americans. So, I wanted to eliminate that collection from the data when it was flagged for that term.
Delete rows where MATCHES([FILE], 'ICU.SPCL.CHANDRASEKHAR’, false) && MATCHES([{WORD}], 'Indian', false)
This was a time-intensive step, but worthwhile because it reduced my dataset from nearly 33,000 rows to a little over 11,000 rows (approximately two-thirds of my output was “noise”).
Before feeding my data into visualization software for analysis, I removed the “LINE NUMBER” and “LINE TEXT” columns.
I also categorized my red flag terms and broke the large dataset down into smaller datasets by category. This anticipates the need to do reparative description in phases utilizing different remediation techniques/approaches (first, we’ll tackle terms of aggrandizement, then we’ll look at ableist language, etc.). Categorizing some of the terms felt fraught with subjectivity (see “Bias Bias Bias!” above). However, breaking the data apart in this way resulted in clearer visualizations and made analysis easier.
I added category columns to my dataset (some words might fit in more than one category) so that I could see which types of “red flag” terms occur the most in our finding aids. I saved my cleaned and enhanced dataset as: xml-term-detective-enhanced.csv. See Appendix to download my cleaned and enhanced XML-Term-Detective output.
Categories¶
- Ableism
- Aggrandizement
- Class
- Colonialism
- Incarceration and Forced Removal
- Race, Ethnicity, and Citizenship
- Sexism
- Slavery
Analysis¶
Visualizing the data in Tableau and Neo4j helped me to see trends in the data, enabling me to make decisions about how to prioritize finding aids for reparative description.
Tableau¶
Tableau is a visual data analytics platform. I used a free trial of Tableau Desktop, saved the dashboards to my computer should I ever have access to Tableau Desktop again, and uploaded the finished visualizations to Tableau Public. Tableau Public is free and can do most things that Tableau Desktop can do. The downside to Tableau Public is an inability to export your visualizations or save your work locally and edit projects privately over time.
Neo4j¶
Neo4j is a graph database platform. A graph database stores nodes and relationships instead of tables, or documents. I used the Neo4j Desktop app (free one-year trial if you are a student as of this writing) to visualize the “worst offender” finding aids (those with the highest red flag term counts). A zip file containing all of my "worst offender" Neo4j graphs (more than are rendered in this Notebook) is available for download in the Appendix.
Getting Started Guide for Neo4j
Start a Project in Neo4j and upload your data.
Neo4j uses its own “cypher” language. (Pro tip: Cypher can easily break if something isn’t typed just write. For each of the cypher commands that I used, I needed to delete and retype the double or single quotation marks in my command to get it to work.)
To load my data into Neo4j, I used the following cypher command:
LOAD CSV WITH HEADERS FROM “file:///xml-term-detective-enhanced.csv” AS row MERGE (f:File {Filename: row.FILE}) MERGE (w:Word {RedflagTerm: row.WORD}) MERGE (c:Category {Type: row.CATEGORY1}) MERGE (f)-[rf:Has_redflag_term]->(w) MERGE (w)-[ct:Has_category]->(c) RETURN f, w, c, rf, ct
To visualize the red-flag terms and categories in a particular finding aid, I used the following command:
MATCH (f:File {Filename: 'ICU.SPCL.TAXSOL.xml'})-[Has_redflag_term]-(w:Word) MATCH (c:Category) RETURN f, w, c
To see all the red flag terms in a particular category:
MATCH (c:Category {Type: 'aggrandizement'})-[]-(w:Word) RETURN c, w
To see all of the finding aids that contain a particular red flag term:
MATCH (f:File)-[Has_redflag_term]-(w:Word {RedflagTerm: 'girl'}) RETURN f, w
To see all of the red flag terms in a particular finding aid:
MATCH (f:File {Filename: 'ICU.SPCL.STEINERJ.xml'})-[Has_redflag_term]-(w:Word) RETURN f, w
Overview of Tableau Visualizations for Full Dataset¶
I created visualizations for the full dataset, and I created visualizations for the smaller sets of categorized data. I created Dashboards for each category, and then strung the Dashboards together into a Tableau Story. (A static PDF version of all Tableau visualizations is availabe for download in the Appendix.)
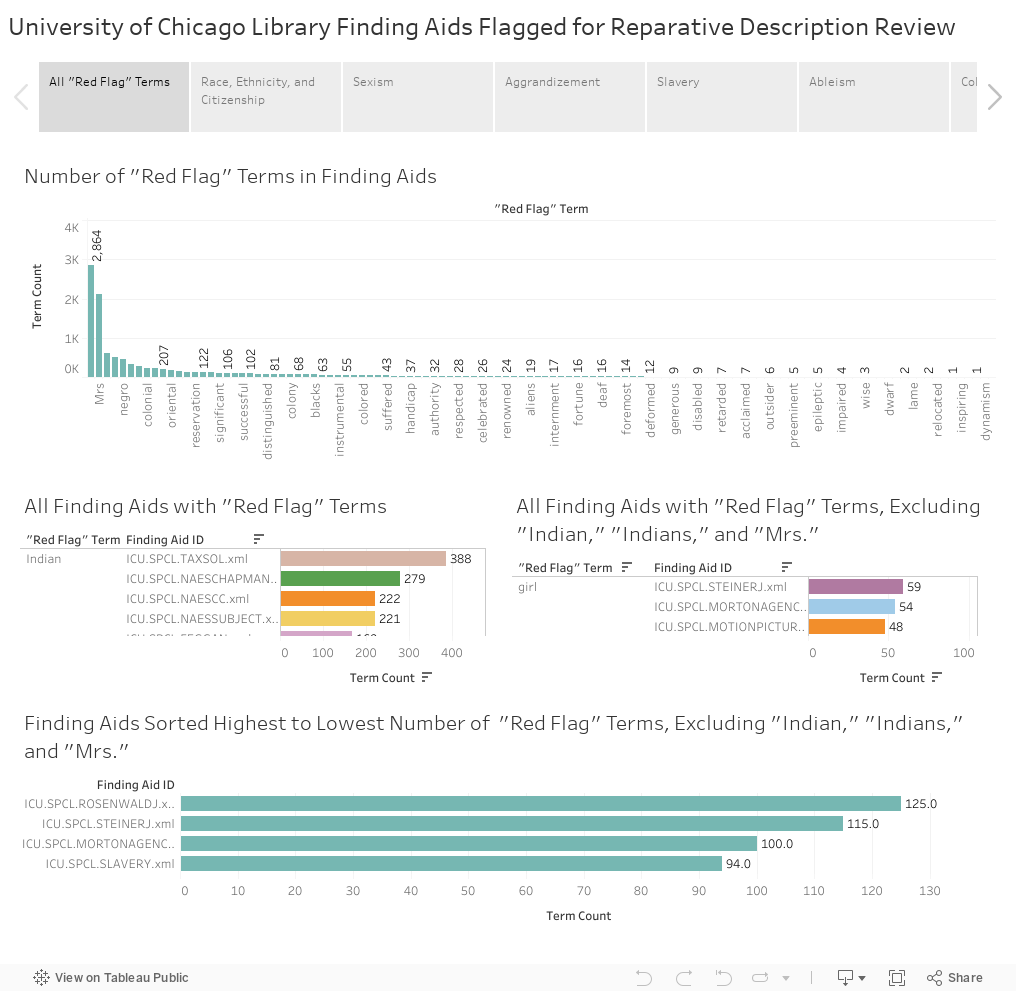
I created five visualizations of all “red flag” terms:
- A histogram showing the number of times a “red flag” term appears across all of UChicago’s finding aids. Terms are arranged from highest count to lowest.
- A histogram showing the number of “red flag” terms in each category. (Not in Tableau Story)
- A bar graph showing all “red flag” terms from highest count to lowest count, and the finding aids that contain that term.
- The same bar graph as above, excluding the top three “red flag” terms, “Indian, “Indians, and “Mrs.” These terms far outweigh other terms, and excluding them helped me to see other problem areas.
- A histogram showing finding aids arranged from “worst offender” (highest term count) to “least offender” (lowest term count), excluding those flagged for the terms “Indian,” “Indians,” and “Mrs.”
These visualizations indicate that we have the most review work to do for finding aids with language about race, ethnicity, and citizenship. Terms “Indian” and “Indians” make up 71% of the race, ethnicity, and citizenship category. Finding aids containing terms about women are the next highest category, with the term “Mrs.” accounting for 80% of that category. Terms of aggrandizement are the third-highest category.
If “Indian,” “Indians,” and “Mrs.” are excluded, the top three categories remain the same, but terms of aggrandizement take the lead, followed by race, ethnicity, and citizenship terms, then sexist language.
The following analyses reflect the second histogram and are arranged by category from those with the highest red flag term counts to those with the lowest term counts.
Race, Ethnicity, Citizenship¶
I created five Tableau visualizations of race, ethnicity, and citizenship terms:
- A histogram showing the number of times a “red flag” term in this category appears across all UChicago finding aids.
- A bubble graph showing the top terms in this category across all UChicago finding aids.
- A bar graph showing terms in this category from highest count to lowest, and the finding aids that contain them.
- A histogram showing finding aids arranged from “worst offender” in this category (highest term count) to “least offender” (lowest term count).
- A histogram showing finding aids arranged from “worst offender” to “least offender” in this category, with “Indian” and “Indians” excluded.
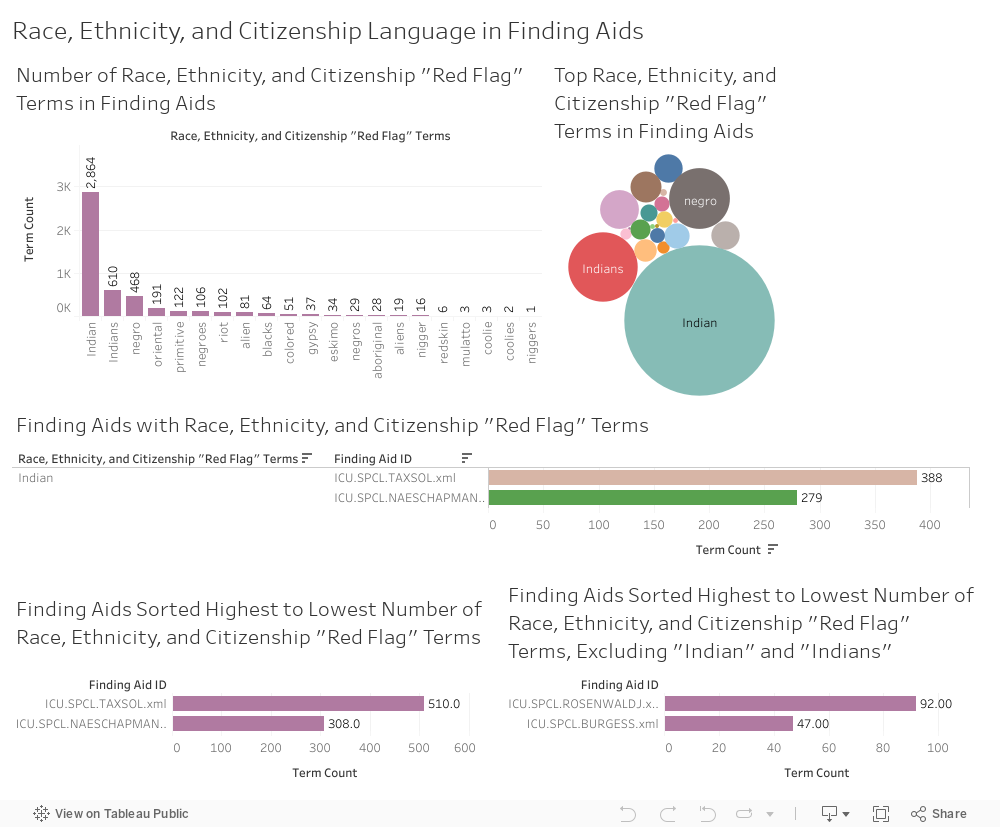
The terms “Indian,” “Indians,” “negro,” “negroes,” “oriental,” and “primitive” account for 90% of the terms in this category.
The Sol Tax Papers finding aid contains the highest counts of “Indian” and “Indians,” and the most terms in this category overall.

Many finding aids from our Native American Educational Services collections account for some of the highest instances of “Indian” and “Indians,” which is unsurprising.
The Julius Rosenwald Papers finding aid has the highest counts of “negro” and “negroes.”

The Paul Kraus Papers finding aid contains the most instances of “oriental,” and the Robert Redfield Papers finding aid contains the most instances of “primitive.”
Sexism¶
I created four visualizations in this category:
- A histogram showing the number of times a “red flag” term in this category appears across all UChicago finding aids.
- A bar graph showing terms in this category from highest count to lowest, and the finding aids that contain them.
- A histogram showing finding aids arranged from “worst offender” for the red flag “Mrs.” (highest term count) to “least offender” (lowest term count).
- A histogram showing finding aids arranged from “worst offender” for the red flag “girl” (highest term count) to “least offender” (lowest term count).
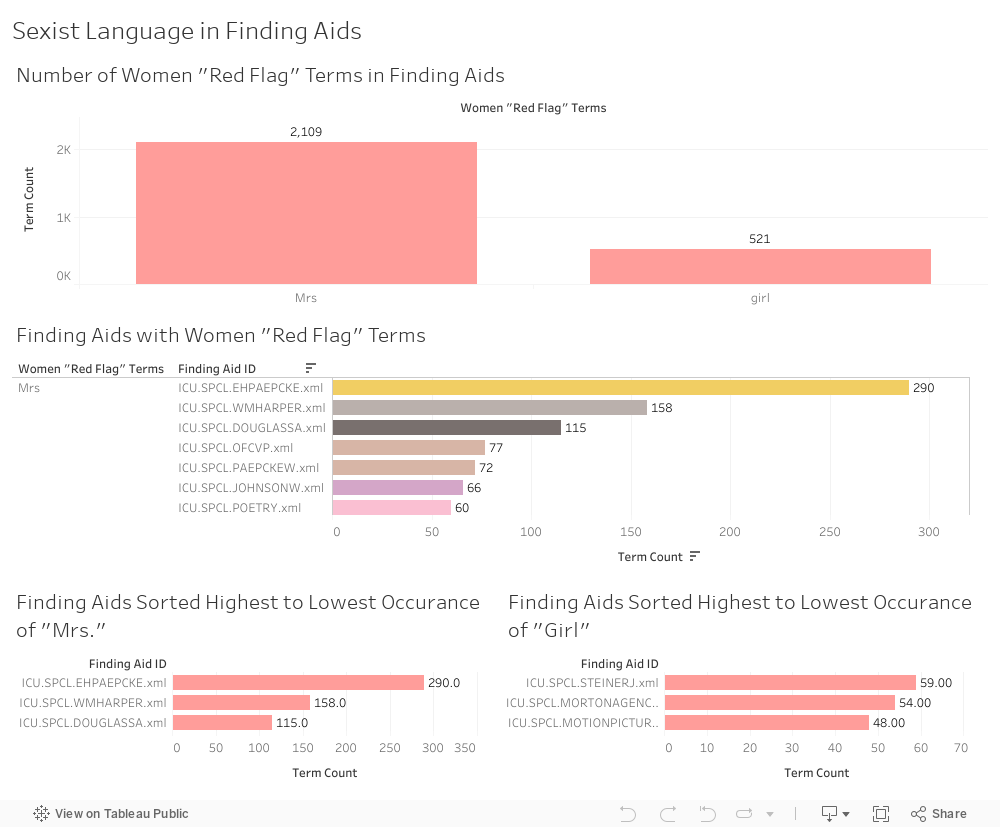
The red flag term “Mrs.” far outweighs “girl” in this category. Anticipating that review and possible remediation of “Mrs.” and “girl” will require different approaches, I graphed the worst offending finding aids for those terms separately.
Three finding aids account for 76% of occurrences of “Mrs.”:
- Paepcke, Elizabeth H. Papers (Neo4j graph below)
- Harper, William Rainey. Papers
- Douglas, Stephen A. Papers

13 finding aids have double-digit occurrences of “girl” and account for 58% of this term:
- Steiner, John. Collection (Neo4j graph below)
- Morton, Charles, Agency. Collection of American Popular Drama
- Motion Picture Stills. Collection
- Song Sheet and Broadside Poem. Collection
- Manning, Richard. Band. Collection
- Noyes, Ida. Papers
- Willis, Alfred. Collection of African-American Popular Fiction
- Eggan, Joan Rosenfels. Papers
- Popular Literature. Collectio
- Burgess, Ernest Watson. Papersli>
- Burgess, Ernest Watson. Papers. Addenda
- Goldman, Samuel. Papers
- Jazz Piano Song Sheet. Collection

Aggrandizement¶
I created four visualizations of terms of aggrandizement:
- A histogram showing the number of times an aggrandizing “red flag” term appears across all UChicago finding aids.
- A bubble graph showing the top terms of aggrandizement across all UChicago finding aids.
- A bar graph showing terms of aggrandizement from highest count to lowest, and the finding aids that contain them.
- A histogram showing finding aids arranged from “worst offender” in this category (highest term count) to “least offender” (lowest term count).
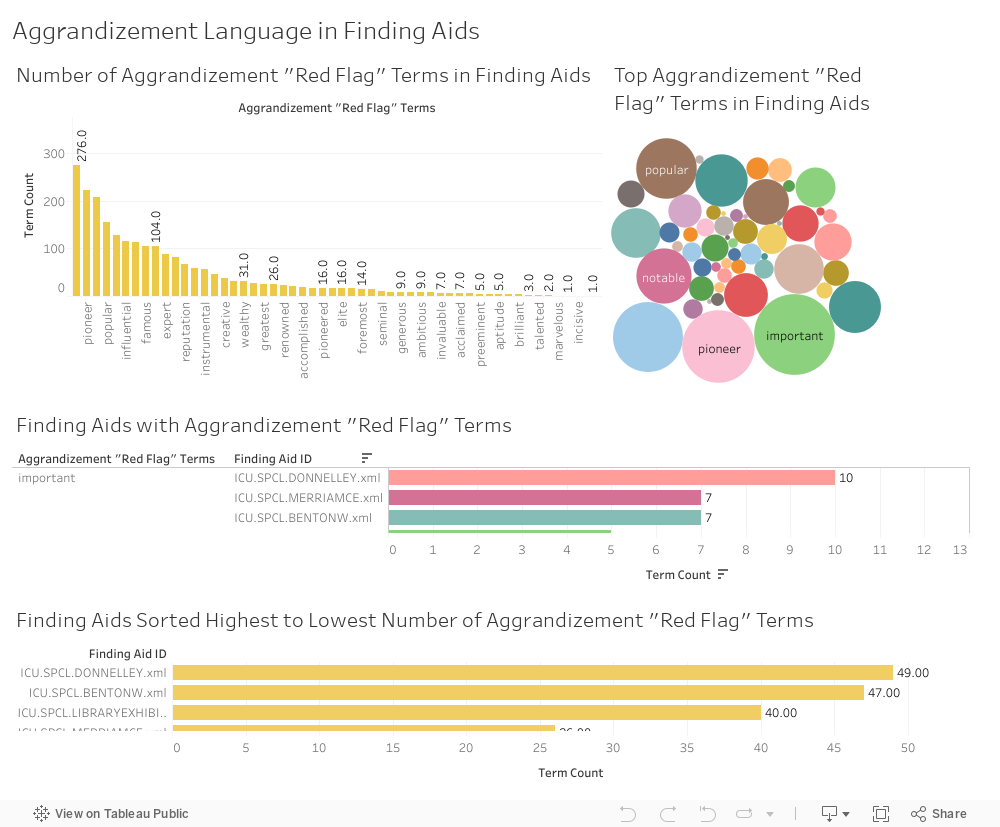
The terms “important,” “pioneer,” “prominent,” “popular,” and “notable” account for 44% of the aggrandizement category.
There are 33 finding aids with double-digit terms of aggrandizement, and together these account for 25% of aggrandizing language across all UChicago finding aids.
The top five “worst offenders” in this category are:
- R.R. Donnelley and Sons Company. Archive (Contains most instances of “important.” Neo4j graph below.)
- Benton, William. Papers (Neo4j graph below.)
- University of Chicago. Library. Exhibit Publications. Collection
- Merriam, Charles E. Papers
- Klutznick, Philip M. Papers (Contains most instances of “notable.”)


Slavery¶
I created four visualizations in this category:
- A histogram showing the number of times a “red flag” term in this category appears across all UChicago finding aids.
- A bar graph showing terms in this category from highest count to lowest, and the finding aids that contain them.
- The same bar graph as above, with the finding aid for the “Slavery in North America Collection” excluded.
- A histogram showing finding aids arranged from “worst offender” in this category (highest term count) to “least offender” (lowest term count).
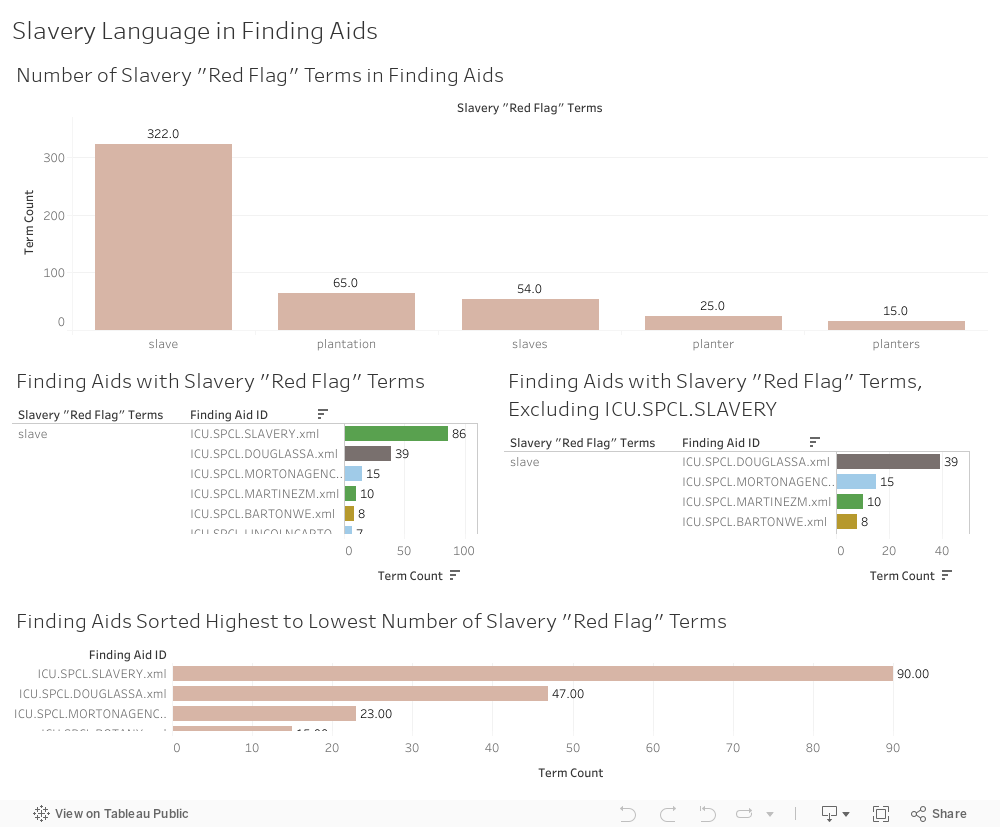
The terms “slave” and “slaves” account for 78% of red flag terms in this category. Unsurprisingly, these terms occur most often in the finding aid for our Slavery in North America Collection. Excluding that collection (which was recently reprocessed using reparative description practices), the “worst offender” finding aids in this category with double-digit red flag terms are:

Ableism¶
I created four visualizations of ableist language:
- A histogram showing the number of times an ableist “red flag” term appears across all UChicago finding aids.
- A bubble graph showing the top ableist terms across all UChicago finding aids.
- A bar graph showing ableist terms from highest count to lowest, and the finding aids that contain them.
- A histogram showing finding aids arranged from “worst offender” in this category (highest term count) to “least offender” (lowest term count).
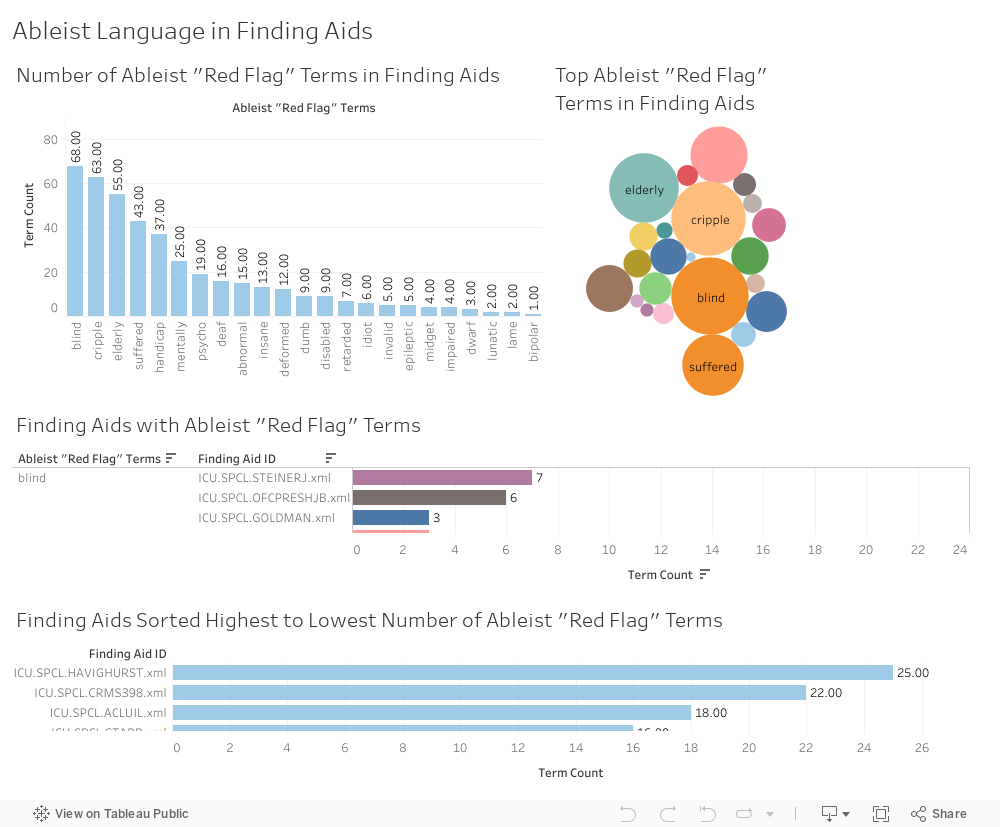
The terms “blind,” “cripple,” “elderly,” “suffered,” and “handicap” account for 63% of the ableism category.
There are five finding aids with double-digit ableist terms, and together these account for 21% of ableist language across all UChicago finding aids:
- Havighurst, Robert J. Papers (Contains most instances of term “elderly.” Neo4 j graph below.)
- Histories of Pediatric Hospitals. Collection/Crerar Ms 398 (contains most instances of term “cripple”)
- American Civil Liberties Union. Illinois Division. Records (contains most instances of term “handicap”)
- Starr, Frederick. Papers
- Fishbein, Morris. Papers

Colonialism¶
I created three visualizations in this category:
- A histogram showing the number of times a “red flag” term in this category appears across all UChicago finding aids.
- A bar graph showing terms in this category from highest count to lowest, and the finding aids that contain them.
- A histogram showing finding aids arranged from “worst offender” in this category (highest term count) to “least offender” (lowest term count).
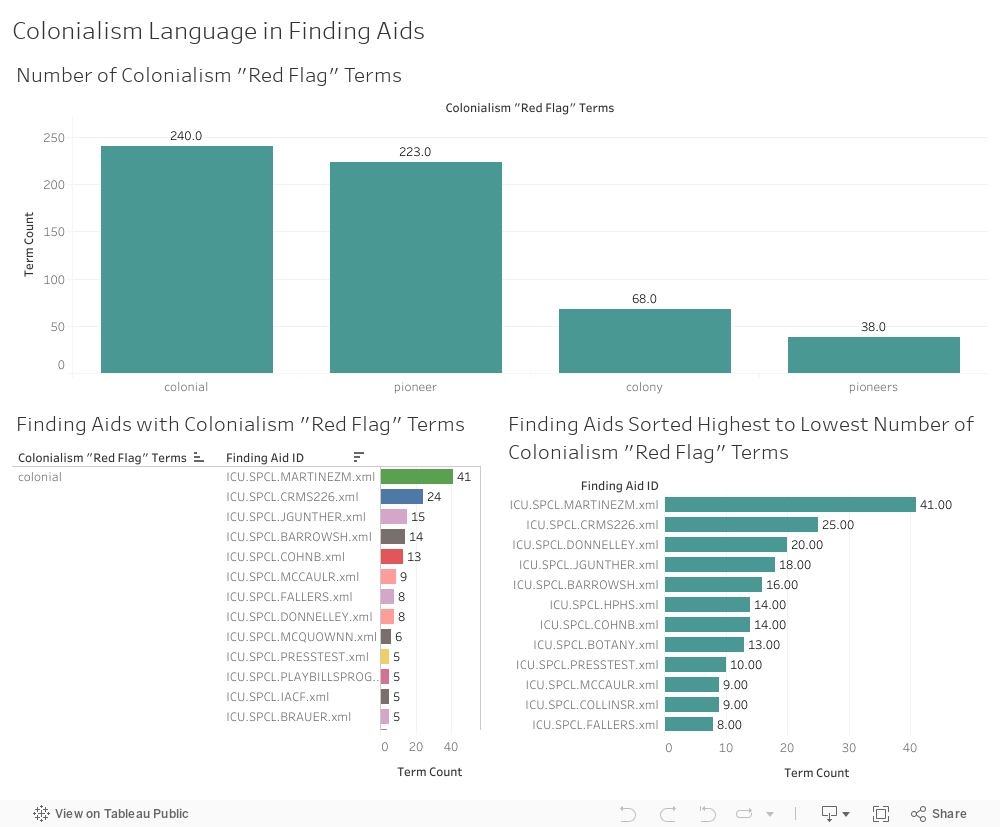
Terms in this category appear 346 times across all UChicago finding aids. Nine finding aids have double-digit counts of terms in this category, and account for 49% of the total term count in this category:
- Martinez, Maria Elena. Papers (Martinez studied Colonial Mexico.)
- Century of Progress International Exposition Publications (Crerar Manuscript 226. Neo4j graph below.)
- R.R. Donnelley and Sons Company. Archive
- Gunther, John. Papers
- Barrows, Harlan H. Papers
- Hyde Park Historical Society Collection
- Cohn, Bernard. Papers
- University of Chicago. Department of Botany. Records
- University of Chicago Press. Records

Incarceration and Forced Removal¶
I created three visualizations in this category:
- A histogram showing the number of times a “red flag” term in this category appears across all UChicago finding aids.
- A bar graph showing terms in this category from highest count to lowest, and the finding aids that contain them.
- A histogram showing finding aids arranged from “worst offender” in this category (highest term count) to “least offender” (lowest term count).
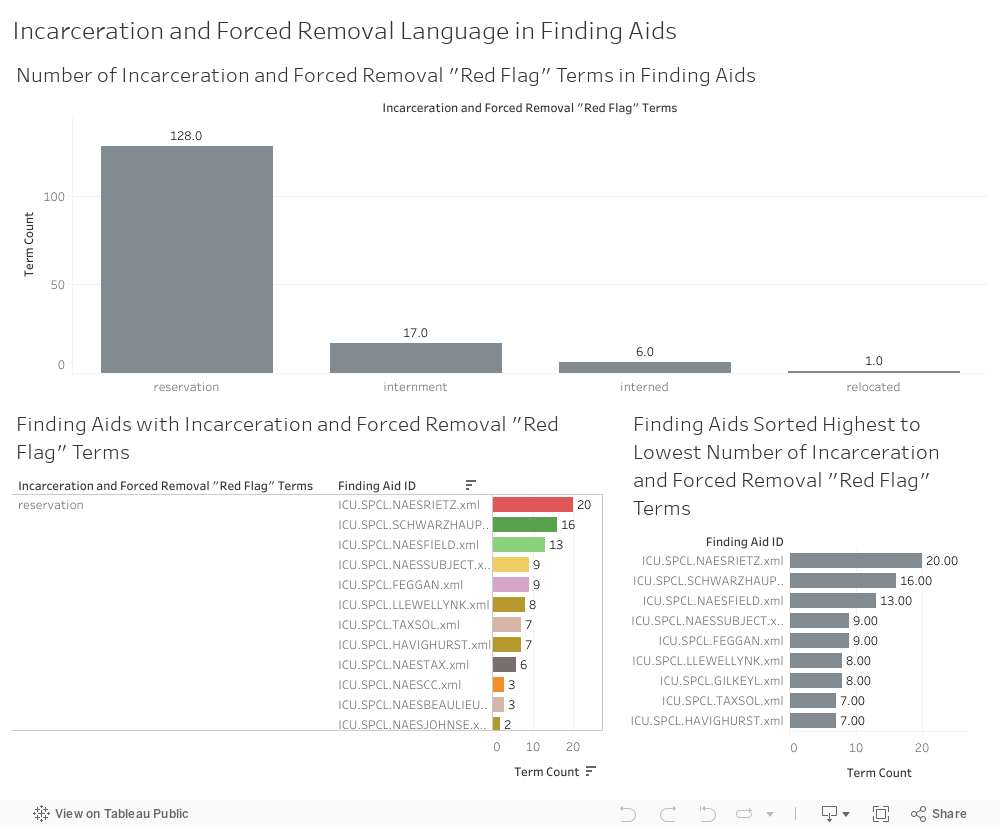
The term “reservation” far outweighs other terms in this category, accounting for 84% of red flag terms in this category. Nearly one-third of red flag terms in this category occur in three finding aids:

Class¶
I created three visualizations of class terms:
- A histogram showing the number of times a “red flag” term in this category appears across all UChicago finding aids.
- A bar graph showing terms in this category from highest count to lowest, and the finding aids that contain them.
- A histogram showing finding aids arranged from “worst offender” in this category (highest term count) to “least offender” (lowest term count).
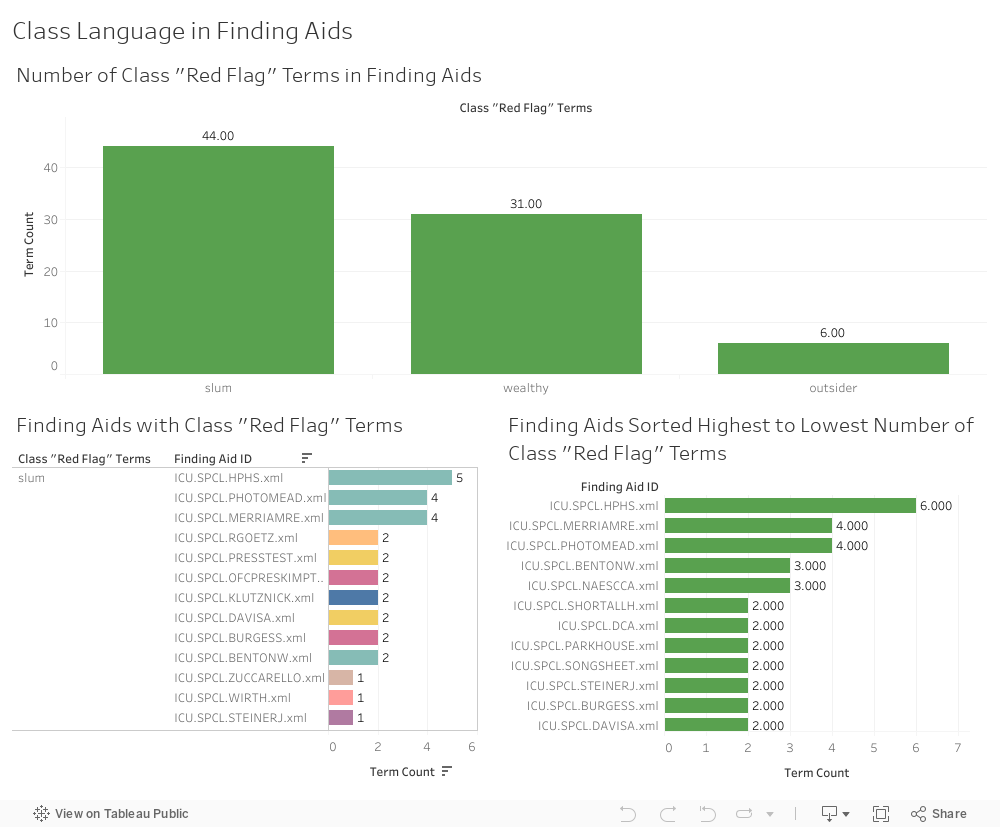
“Slum” occurs the most often across all UChicago finding aids and accounts for 54% of this category. The Hyde Park Historical Society Collection finding aid has the most terms (6) in this category, and the most instances of the word “slum” (5).

Recommendations¶
Workflow¶
There is no one-size-fits-all approach to reparative description. Remediation of legacy metadata will take time, and a careful case-by-case analysis.
One could start at the top of the “worst offender” finding aid list and work your way down the list, finding aid by finding aid.
I suggest approaching the work in phases, and structuring it by red flag term category, moving from categories with the highest term counts to categories with the lowest term counts.
Again, that order is:
- Race, Ethnicity, and Citizenship
- Sexism
- Aggrandizement
- Slavery
- Ableism
- Colonialism
- Incarceration and Forced Removal
- Class
My analysis of the data indicates that we have a lot of collections to review related to Native Americans. This suggests that we could have a lengthy reparative description project devoted solely to Native American and other Indigenous collections, separately from other finding aids in the “Race, Ethnicity, and Citizenship” category.
A reminder that LGBTQ+ terms were not included in this planning project. That does not mean that reparative description of LGBTQ+ collections is less important or should come last. As explained in my discussion of the lexicon, LGBTQ+ collections require a different approach to data gathering and project planning. I strongly suggest that work on LGBTQ+ finding aids be a high priority alongside Race, Ethnicity, and Citizenship finding aids.
There will likely be a learning curve for each category, and productivity may increase if focused attention is given to finding aids one category at a time. There will be an overlap between categories (race, ethnicity, citizenship, colonialism, slavery, incarceration and forced removal are all intertwined), so knowledge gained in one category will likely influence another with the potential for revisiting some categories.
Until staffing levels are increased and significant resources are devoted to reparative description at the University of Chicago Library Hanna Holborn Gray Special Collections Research Center, I recommend reviewing finding aids from “worst offender” to “least offender” in a category. Use of the original XML-Term-Detective output is advised for quickly identifying the line number and text containing a red flag term. This is an imperfect, but simple and quick way to prioritize finding aids for reparative description. The final dataset is far from perfect, and it is very possible that some of the “worst offenders” will prove to be noise in the data. I also acknowledge that offense caused by a single red flag term (such as a slur) in a finding aid could be greater than offense caused by a finding aid with multiple red flag terms.
If an institution has the time and resources, a triage system could be developed to prioritize finding aids for reparative description. Criteria could be developed that sift finding aids into levels from most to least urgent. This is the approach taken by the Getty Research Institute’s Anti-Racist Description Working Group. See their rubric. This is time-intensive, subjective work that requires a person to review each finding aid one by one.
A project manual should be developed for each category that includes style guides and controlled vocabularies relevant to that category.
Ideally, the project manual would be developed in consultation with subject experts and with living individuals or communities whose records are described. This is especially important for finding aids in the Race, Ethnicity, and Citizenship category. All consultants should be compensated for their time and labor.
Policy Setting and Editing Finding Aids¶
Reparative description of finding aids should take several forms:
- Removing and updating language OR
- Keeping language in place, but adding contextualization and additional keywords for discoverability AND
- Adding a collection-level content warning about the presence of harmful, biased, or culturally sensitive metadata.
- Adding additional description to improve discoverability, including access terms for “hidden figures” and bilingual description for collections containing significant amounts of non-English-language materials.
- Adding an obvious and easy feedback mechanism for finding aid users.
Many red flag terms appear in original folder headings or titles of published works. In cases such as this, I recommend keeping the language in place, adding a content warning to the finding aid, and any additional contextualizing metadata deemed necessary.
Reasons for when and why to remove or keep harmful language should be clearly spelled out in a Reparative Description Policy. Guidelines for how to apply the policy should be incorporated in each project manual.
Resources¶
Archives for Black Lives in Philadelphia Anti-Racist Description Resources
Australian Institute of Aboriginal and Torres Strait Islander Studies, AustLang controlled vocabulary for Aboriginal and Torres Strait Islander languages
Brown, Lydia X. Z., Glossary of Ableist Language
Cataloging Lab, List of Statements on Bias in Library and Archives Description
DEI Controlled Vocabs Resource List
First Archivist Circle, Protocols for Native American Archival Materials
Foreman, P. Gabrielle, et al. “Writing about Slavery/Teaching About Slavery: This Might Help”
Frick, Rachel L., and Merrilee Proffitt. 2022. Reimagine Descriptive Workflows: A Community-informed Agenda for Reparative and Inclusive Descriptive Practice. Dublin, OH: OCLC Research
Homosaurus, an International LGBTQ+ Linked Data Vocabulary
Indigenous Corporate Training, Inc., Indigenous Peoples terminology guidelines for usage
Local Contexts, TK Labels
Mizota, Sharon. Free Resources About Bias and Metadata
National and State Libraries Australasia, Culturally Safe Libraries Program Resources
National Center on Disability and Journalism, Disability Language Style Guide
Society of American Archivists, Description Section, Inclusive Description resources
Society of American Archivists, Native American Archives Section, Implementing Reparative Description for Indigenous Collections
Trans Metadata Collective, Metadata Best Practices for Trans and Gender Diverse Resources
University of Nevada, Las Vegas Native American Names Cross Reference
Wilson Special Collections Library, University of North Carolina Chapel Hill, A Guide to Conscious Editing at Wilson Special Collections Library, (download)
Young, Gregory. Elements of Indigenous Style: A Guide for Writing by and About Indigenous Peoples
Examples¶
Clemens, Alison, Jennifer Coggins, Michelle Peralta, and Jessica Tai,, “Addressing Missing Name Information for Women in Yale Special Collections,” Descriptive Notes, Society of American Archivists Description Section.
Bredbenner, Stephanie and Jessica Tai, “Remediating Euphemistic Language in Yale’s Collections Documenting Japanese American Incarceration,” New England Archivists Newsletter. Vol. 48, no. 1 (2021): 5-7.
Brewer, Celeste. “Processing LGBTQ Collections Then and Now,” Archival Outlook. May/June 2018: 4-5.
Morretti, Annalisa. “Reparative Description of Disability Collections,” Archival Outlook. Nov/Dec 2021: 8-9.
Suárez, Armando, “Spanish-Language Finding Aids at Princeton University Library,” Descriptive Notes, Society of American Archivists Description Section.