Data Modeling¶
Initial Assignment¶
This project grew out of an assignment for the INST742 course that I completed earlier in the semester. For that assignment, the goal was to use the dataset in its original structure for creating a simple graph database, and then query that database to see if any interesting insights about relationships emerged. You can view the original dataset here.
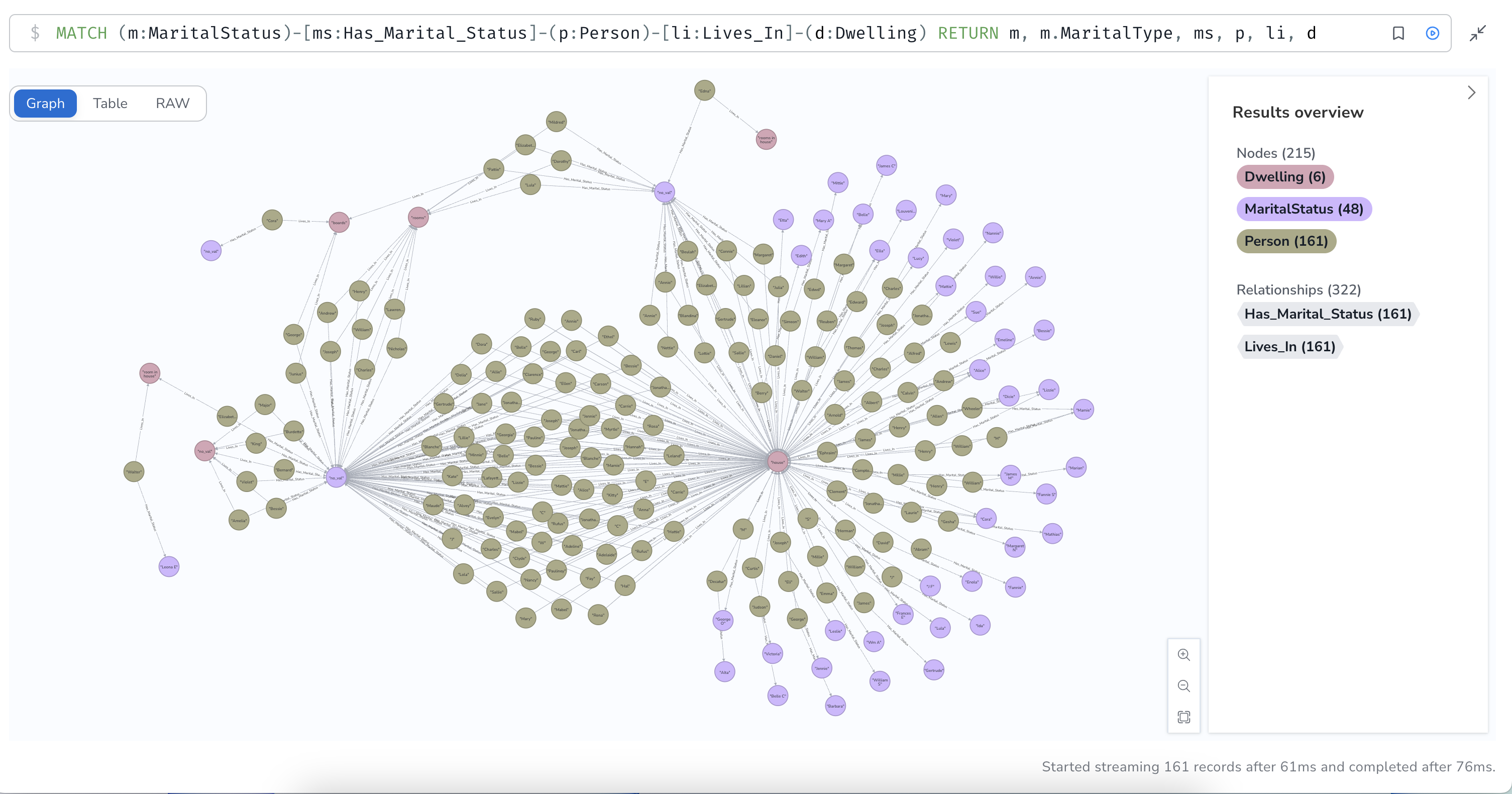
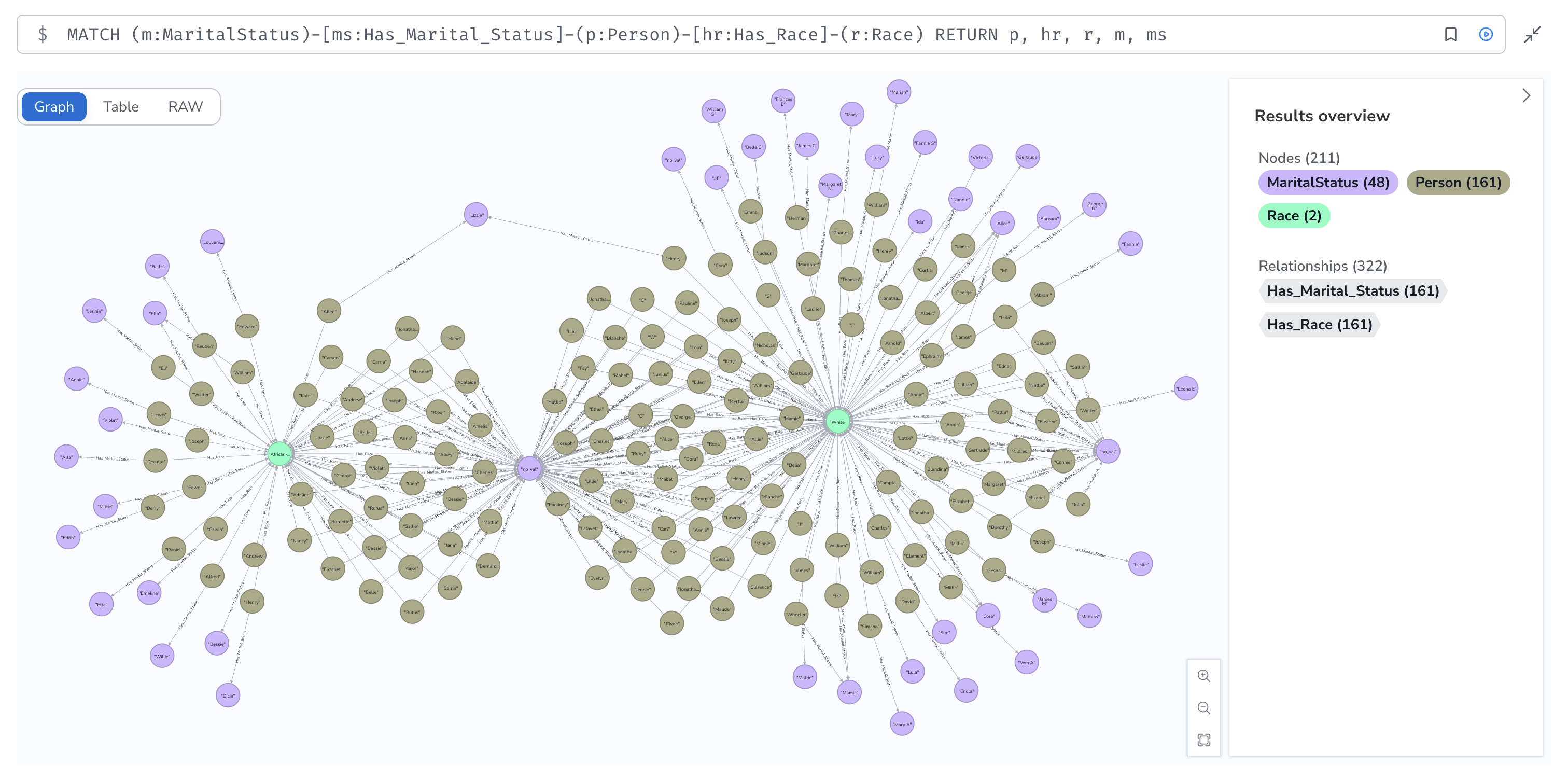
I was able to generate some intriguing queries, but ran into some issues because of the way certain relationships were represented. Specifically, the representation of marriage relationships, residences and residence types had been flattened and lacked complexity.
Downsides of Previous Data Model¶
The data model originally used for the Neo4j assignment in this course was almost too faithful to the structure of the original source data, to the point where it didn't really provide an accurate representation of the relationships contained within the directory. To further investigate this, I started by reverse-engineering a flowchart to represent the original data model, using this to identify the aspects I wanted to modify.
I used the Arrow.apps tool (a browser-based whiteboard style modeling tool produced by Neo4j) to illustrate this model:
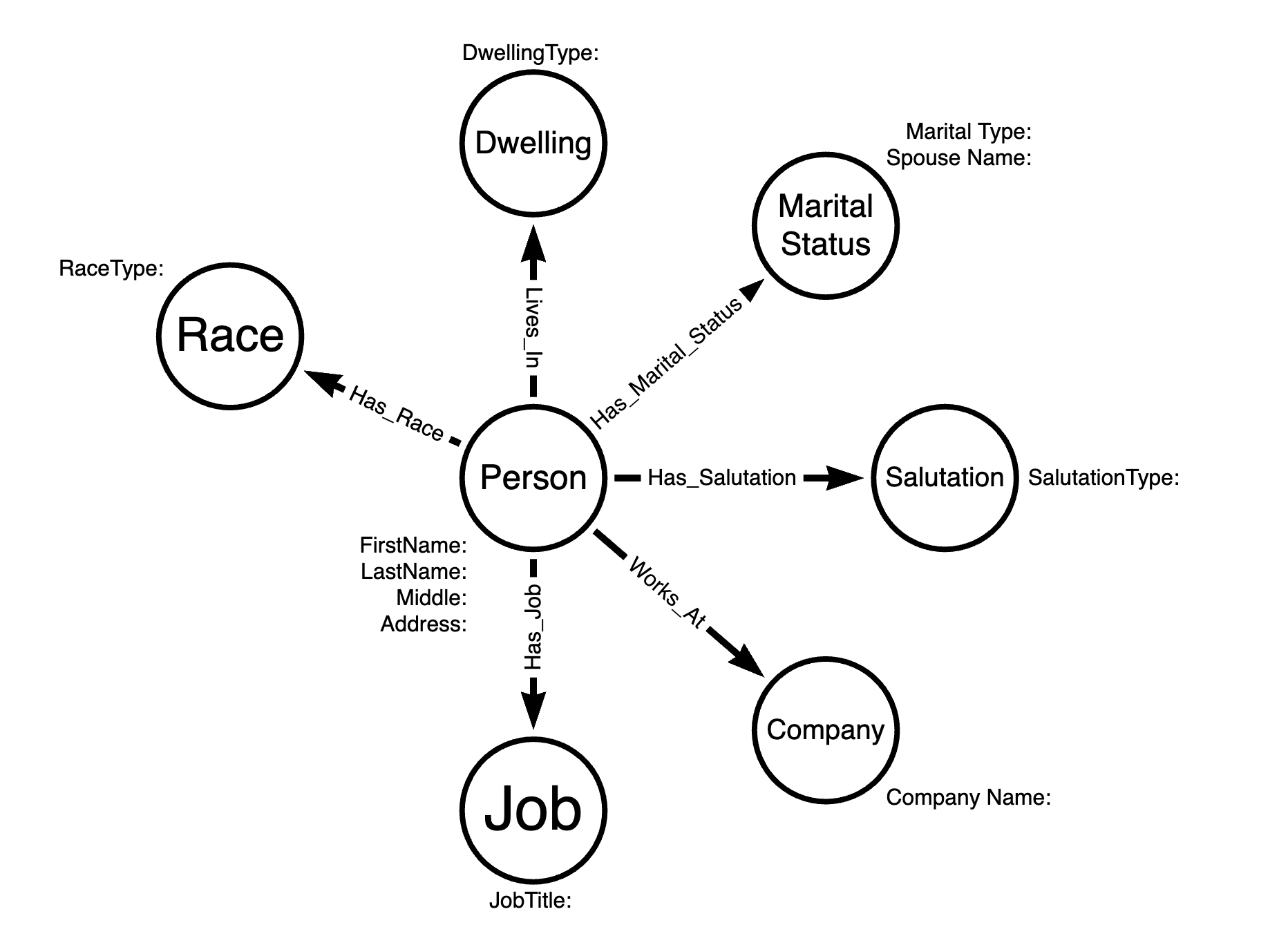
As you can see, spouses are not given their own nodes and instead are listed as a property of the MaritalStatus node, making it difficult to analyze marriage relationships. Also, address is listed as a property of a person, instead of being related to dwelling type.
New Data Model¶
Conceptual Modeling¶
I wanted my new data model to address the flaws I had found in the previous model, and so I started sketching possible versions, using the kinds of queries I hope to be able to answer to guide the design process. When I settled on a version that seemed the most promising, I created it in Arrow.apps again to have a cleaner representation:
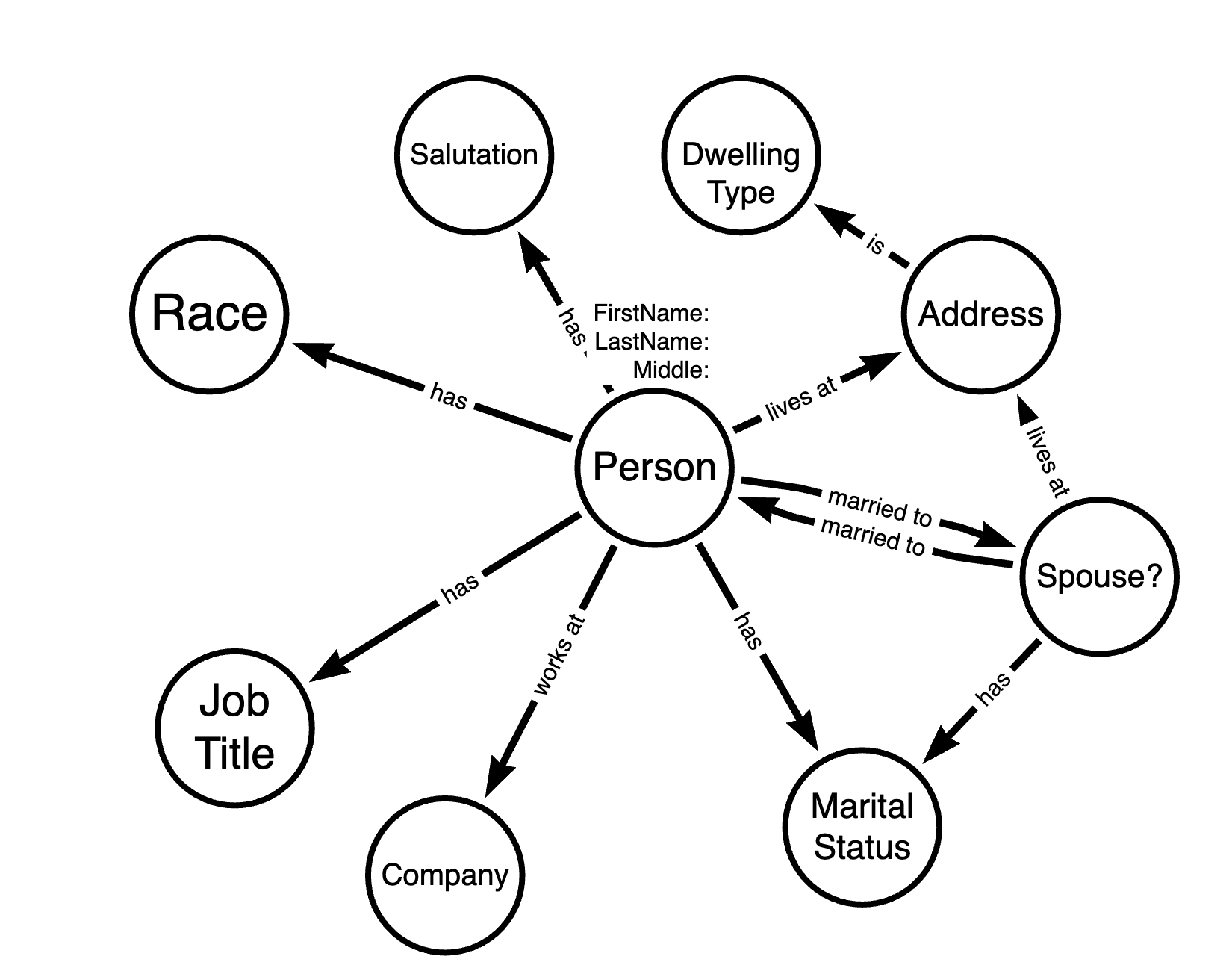
As you can see, this model is focused on the fact that everything radiates out from the Person node, and is based in the idea that separating out more aspects of a given Person into distinct nodes opens up greater possibilities for querying the database in different ways. Specifically, I wanted any property that could possibly be shared to be a node, and wanted anything I might want to search on (that wasn't a relationship) to be a node as well. It's much easier to search on nodes than it is to search on properties or metadata, so I wanted my data model to take advantage of that aspect of Neo4j.
The major changes I made include separating out Spouse as a distinct node type (it's actually another Person node, but for the sake of illustration it's labeled as Spouse here), separating out Address as a distinct node type, and creating a relationship between Address nodes and Dwelling Type nodes, instead of having a relationship between Person nodes and Dwelling Type nodes.
Modifications to CSV¶
I used Excel filtering and conditional formatting capabilities to streamline the data manipulation process, then converted it back to a CSV file later on for ingest into Neo4j. The most significant change I made was the creation of separate rows for the people listed only as spouses in the original directory dataset so that they would be listed as distinct individuals.
I then filled in the new rows with as much information as I had about the individuals. I felt that I could safely assume that the address (and by extension, dwelling type) would be the same, as well as marital status. I was not comfortable assuming the race of spouses - while while technically interracial marriage was still illegal in NC at this time, I didn’t want to discount the possibility that people had skirted around that law, and so chose to list race as NULL for any new records.
I also created the PersonID and MarriedTo columns because they became necessary for the data ingest process, but they were not part of my intial modifications and so will be explained later. Here is the finished CSV.
Next: Database Creation