Database Creation¶
Preparing Create Script¶
With relational database management systems like MySQL, you typically construct a logical model of your database and then instruct the system to forward engineer the model into a physical database. In Neo4j, you have to write the code to create the database yourself, using the Cypher language, and while this is a little more labor-instensive, it gives you a higher level of control over the creation of the database and more ability to fine-tune things.
Original Create Script¶
The create script used for the graph database in the original assignment, as described in the previous notebook, looked like this:
LOAD CSV WITH HEADERS FROM "file:///Charlotte1911_new.csv" AS row
MERGE (p:Person {FirstName: row.First, LastName: row.LastName, MiddleInitial: row.Middle, Address: row.Address})
MERGE (d:Dwelling {DwellingType: row.Dwelling})
MERGE (r:Race {RaceType: row.Race})
MERGE (m:MaritalStatus {MaritalType: row.MaritalStatus, SpouseName: row.Spouse})
MERGE (s:Salutation {SalutationType: row.Salutation})
MERGE (c:Company {CompanyName: row.Company})
MERGE (j:Job {JobTitle: row.JobTitle})
MERGE (p)-[li:Lives_In]->(d)
MERGE (p)-[hr:Has_Race]->(r)
MERGE (p)-[ms:Has_Marital_Status]->(m)
MERGE (p)-[hs:Has_Salutation]->(s)
MERGE (p)-[pc:Works_At]->(c)
MERGE (p)-[jn:Has_Job]->(j)
Modified Create Scripts¶
The final create script I eventually developed looks like this, but only after several rounds of experimentation:
LOAD CSV WITH HEADERS FROM "file:///Charlotte1911_mod.csv" AS row
MERGE (p:Person {PersonID: row.PersonID})
ON CREATE SET p.FirstName = row.First, p.LastName = row.LastName, p.MiddleInitial = row.Middle
MERGE (s:Salutation {SalutationType: row.Salutation})
MERGE (r:Race {RaceType: row.Race})
MERGE (j:Job {JobTitle: row.JobTitle})
MERGE (c:Company {CompanyName: row.Company})
MERGE (m:MaritalStatus {MaritalType: row.MaritalStatus})
MERGE (a:Address {StreetAddress:row.Address})
MERGE (d:Dwelling {DwellingType: row.Dwelling})
MERGE (p) - [hs:HasSalutation] -> (s)
MERGE (p) - [hr:HasRace] -> (r)
MERGE (p) - [hj:HasJob] -> (j)
MERGE (p) - [wa:WorksAt] -> (c)
MERGE (p) - [ms:HasMaritalStatus] -> (m)
MERGE (p) - [la:LivesAt] -> (a)
MERGE (a) - [ia:IsA] -> (d)
Eagle-eyed readers will notice that this script doesn't contain a "MarriedTo" relationship. That's because creating relationships between nodes of the same type (in this case, person to person) wasn't particularly intuitvive. I found it easier to do two loads: one for the records themselves and the more simple relationships, then a second for the marriage relationships. I relied a lot on Neo4j documentation - This one proved particularly helpful - and the kindness of StackOverflow strangers from years past to help me figure it out. In the end, the secondary create script for marriage relationships looked like this:
LOAD CSV WITH HEADERS FROM "file:///Charlotte1911_mod.csv" AS row
MATCH (person:Person {PersonID: row.PersonID})
MATCH (spouse:Person {PersonID: row.MarriedTo})
MERGE (person) -[mt:MarriedTo]-> (spouse)
Since I am by no means fluent in Cypher, there may indeed be more efficient or more elegant solutions out there, but given the nature of this project I was content to patchwork things together to get to the results I wanted. Through research and troubleshooting, I eventually realized that the use of unique identifiers was going to be necessary in order to clearly define the relationships, hence the inclusion of the "PersonID" and "MarriedTo" columns. These function a lot like primary/foreign keys in relational database systems like SQL – once I made that connection this became a lot easier because of my experience with SQL.
Executing Script and Ingesting Data¶
Because I was loading data from a CSV file (hence the LOAD CSV WITH HEADERS FROM keywords at the beginning of each create script), these scripts actually create the database and populate it with data from the CSV at the same time. It took a lot of troubleshooting to arrive at the code included above because no matter how conscious I was in my drafting, I still had to test the code to make sure it worked. This process involved a lot of back and forth: draft a load script, run it, see what the graph looked like, find an issue, go back and edit the script, delete the previous version of the database from my server, rinse and repeat.
Here are some samples of early test code, when I was trying to see if I could get Neo4j to build the relationships I wanted without me having to modify the CSV too much (which did not work, as you saw in the previous notebook):
#test load script with just people
LOAD CSV WITH HEADERS FROM "file:///Charlotte1911_new.csv" AS row
MERGE (p:Person {FirstName: row.First, LastName: row.LastName, MiddleInitial: row.Middle})
MERGE (s:Spouse {FirstName: row.Spouse, LastName: row.LastName})
MERGE (m:MaritalStatus {MaritalType: row.MaritalStatus})
MERGE (p)-[ms:Has_Marital_Status]->(m)
RETURN p, s, m, ms
#test load script round two
LOAD CSV WITH HEADERS FROM "file:///Charlotte1911_mod.csv" AS row
MERGE (p:Person {FirstName: row.First, LastName: row.LastName, MiddleInitial: row.Middle})
MERGE (m:MaritalStatus {MaritalType: row.MaritalStatus})
MERGE (p)-[ms:Has_Marital_Status]->(m)
MERGE (p)-[mt:MarriedTo]->(p)
Full Graph Display¶
The complete graph, with all 48 individuals and associated information, turned out like this:
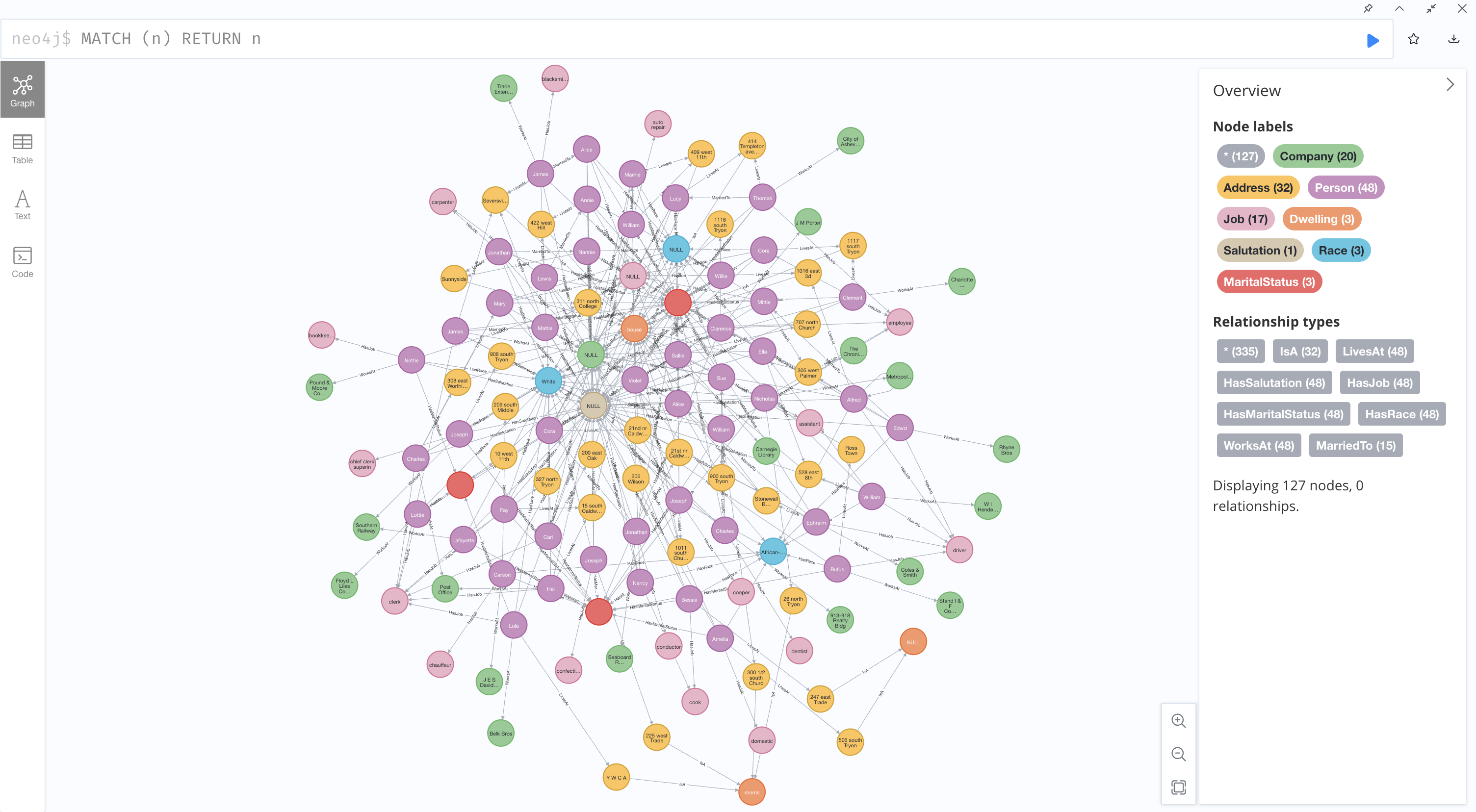
With this smaller dataset, it's possible to pick out some interesting connections, but the real benefit of this data model is its ability to support a broad variety of queries, which we'll look at next.
Next: Results