Curating the #RickyRenuncia Dataset using Schema.org¶
Background¶
Developing a curation for the #RickyRenuncia Dataset that includes relation between the retweets, the quoted tweet, the original tweet and its shared media is important due to the archiving policies of Twitter. Also, the process of curating this dataset will add context of how these pieces of information impacted people, how people reacted to it and how it was shared within the Twitter community. Social networks include multiple cultural manifestations of the Puerto Rican people and more. These expressions together make up part of the collective memory and impact our historical-cultural perceptions. Social media starkly presents the changing political, social, economic and cultural landscape.
It is important to download the content of the tweets quickly since they can be deleted by the user or, given the number of tweets that the user publishes, Twitter can make the decision to archive the tweet making it invisible for other people but not for the user who generated it. Twitter policies do have restrictions on the ways the data can be preserved and shared for posterity, but we are convinced our methodology falls in the scope of Fair-Use. Therefore, it is important not only to create the list of tweet identifiers, but also to generate a curation that allows to standardize the dataset, enrich the tweet and preserve it.
Objectives¶
This jupyter notebook objective is to crosswalk Twitter's data structures to a Social Media Posting metadata schema.The student will be able to appreciate different data strutures such as JSONL, RDFa and JSON-LD.
The main output of this code is to produce two data structures, RDFa and JSON-LD. By using RDFa, the user will be able to display in the notebook the crosswalk with its metadata fields without any CSS customization. By using JSON-LD, the user will be able to appreciate the differences on data structures. In both cases, RDFa and JSON-LD, the user will see the metadata structure needed to implement Schema.org.
It is our hope that this crosswalk will allow us to develop a long term preservation plan of the Twitter dataset that is independent of Twitter API and data structure changes.
Learning goals:¶
- To learn how to perform metadata croswalks between two different schemas.
- Gain understanding on RDF and JSON-LD data structures.
Expected Interaction:¶
The user of this notebook will encounter blocks of pyhton code that will explain each component of the coding process. This jupyter notebook will work over a JSONL formatted document that will be migrated to an RDFa and JSON-LD strcuture.
What is RDF?¶
The W3C School has defined the Resource Description Framework as a model to interchange information in the internet, it supports schemas continous developement and facilitates data merging W3C Schools, RDF .
RDF structure¶
Linked Data uses RDF to provide a graph-based framework to link/reference resources. Since RDF is a data schema it can be represented in a diversity of different formats such as Turtle, TriG, or RDF on XML. Based on RDF triples, each subject in an RDF compliant data structure will be represented as an RDF graph. Each graph may contain information about one or more subjects. Each of these subjects will have either one or more predicates that point to one or more objects.
In any of the representations, subjects and predicates have to be represented by an absolute IRI or a relative-IRI using either a base or a prefix. Objects on the other hand can be represented by IRIs, relative-IRIs using a base or prefix, or can be literal values. When a document is going to use a default RDF vocabulary, it is possible to set a base vocabulary. Any base applied for vocabulary will automatically be considered the base for the namespace IRI. This allows writing short versions of subjects, predicates, and objects. Prefixes also create a reference to an RDF vocabulary and namespace IRI. Prefixes allow the use of multiple RDF vocabularies within the same graph or document.
References:
World Wide Web Consortium(W3C). RDF/XML Syntax Specification. https://www.w3.org/TR/2004/REC-rdf-syntax-grammar-20040210/
World Wide Web Consortium (W3C) Graph-based Data Mode 1.1 Documentation. https://www.w3.org/TR/rdf11-concepts/#data-model
Curate Twitter Data using SocialMediaPosting Schema¶
Twitter utilizes a propietary schema to represent Twitter data. This means that Twitter can change the data structure and specifications of their product, and offer backward compatibility and/or legacy service to satisfy their client needs.
Below there is an example of how Twitter data is being pulled from their API in an JSON format.
{
"created_at":"Fri Jul 19 00:31:42 +0000 2019",
"id":1152013106656079872,
"id_str":"1152013106656079872",
"full_text":"RT @ninofray: No vamos a vacilarle los fake abs por un a\u00f1o. #RickyRenuncia #RickyDictador https://t.co/CWYOMCEpLu",
"truncated":false,
"display_text_range":[
0,
113
],
"entities":{
"hashtags":[
{
"text":"RickyRenuncia",
"indices":[
60,
74
]
},
{
"text":"RickyDictador",
"indices":[
75,
89
]
}
],
"symbols":[
],
"user_mentions":[
{
"screen_name":"ninofray",
"name":"n i n o",
"id":908704166595395585,
"id_str":"908704166595395585",
"indices":[
3,
12
]
}
],
"urls":[
{
"url":"https://t.co/CWYOMCEpLu",
"expanded_url":"https://twitter.com/perlalessandra/status/1152001977355603968",
"display_url":"twitter.com/perlalessandra\u2026",
"indices":[
90,
113
]
}
]
},
"source":"Twitter for iPhone",
"in_reply_to_status_id":null,
"in_reply_to_status_id_str":null,
"in_reply_to_user_id":null,
"in_reply_to_user_id_str":null,
"in_reply_to_screen_name":null,
"user":{
"id":890123263,
"id_str":"890123263",
"name":"Edgar \u26bd\ufe0f",
"screen_name":"Junfcb00",
"location":"",
"description":"UPRM SC:junfcb00",
"url":null,
"entities":{
"description":{
"urls":[
]
}
},
"protected":false,
"followers_count":327,
"friends_count":284,
"listed_count":1,
"created_at":"Fri Oct 19 01:59:11 +0000 2012",
"favourites_count":111913,
"utc_offset":null,
"time_zone":null,
"geo_enabled":true,
"verified":false,
"statuses_count":46558,
"lang":null,
"contributors_enabled":false,
"is_translator":false,
"is_translation_enabled":false,
"profile_background_color":"C0DEED",
"profile_background_image_url":"http://abs.twimg.com/images/themes/theme1/bg.png",
"profile_background_image_url_https":"https://abs.twimg.com/images/themes/theme1/bg.png",
"profile_background_tile":false,
"profile_image_url":"http://pbs.twimg.com/profile_images/1249111605612142593/eBzfrEj8_normal.jpg",
"profile_image_url_https":"https://pbs.twimg.com/profile_images/1249111605612142593/eBzfrEj8_normal.jpg",
"profile_banner_url":"https://pbs.twimg.com/profile_banners/890123263/1561030388",
"profile_image_extensions_alt_text":null,
"profile_banner_extensions_alt_text":null,
"profile_link_color":"1DA1F2",
"profile_sidebar_border_color":"C0DEED",
"profile_sidebar_fill_color":"DDEEF6",
"profile_text_color":"333333",
"profile_use_background_image":true,
"has_extended_profile":false,
"default_profile":true,
"default_profile_image":false,
"following":false,
"follow_request_sent":false,
"notifications":false,
"translator_type":"none"
},
"geo":null,
"coordinates":null,
"place":null,
"contributors":null,
"retweeted_status":{
"created_at":"Thu Jul 18 23:48:37 +0000 2019",
"id":1152002265080725504,
"id_str":"1152002265080725504",
"full_text":"No vamos a vacilarle los fake abs por un a\u00f1o. #RickyRenuncia #RickyDictador https://t.co/CWYOMCEpLu",
"truncated":false,
"display_text_range":[
0,
75
],
"entities":{
"hashtags":[
{
"text":"RickyRenuncia",
"indices":[
46,
60
]
},
{
"text":"RickyDictador",
"indices":[
61,
75
]
}
],
"symbols":[
],
"user_mentions":[
],
"urls":[
{
"url":"https://t.co/CWYOMCEpLu",
"expanded_url":"https://twitter.com/perlalessandra/status/1152001977355603968",
"display_url":"twitter.com/perlalessandra\u2026",
"indices":[
76,
99
]
}
]
},
"source":"Twitter for iPhone",
"in_reply_to_status_id":null,
"in_reply_to_status_id_str":null,
"in_reply_to_user_id":null,
"in_reply_to_user_id_str":null,
"in_reply_to_screen_name":null,
"user":{
"id":908704166595395585,
"id_str":"908704166595395585",
"name":"n i n o",
"screen_name":"ninofray",
"location":"",
"description":"this is the way",
"url":null,
"entities":{
"description":{
"urls":[
]
}
},
"protected":false,
"followers_count":260,
"friends_count":449,
"listed_count":0,
"created_at":"Fri Sep 15 14:48:51 +0000 2017",
"favourites_count":485,
"utc_offset":null,
"time_zone":null,
"geo_enabled":true,
"verified":false,
"statuses_count":1836,
"lang":null,
"contributors_enabled":false,
"is_translator":false,
"is_translation_enabled":false,
"profile_background_color":"000000",
"profile_background_image_url":"http://abs.twimg.com/images/themes/theme1/bg.png",
"profile_background_image_url_https":"https://abs.twimg.com/images/themes/theme1/bg.png",
"profile_background_tile":false,
"profile_image_url":"http://pbs.twimg.com/profile_images/1327750989290430466/01EOtvlZ_normal.jpg",
"profile_image_url_https":"https://pbs.twimg.com/profile_images/1327750989290430466/01EOtvlZ_normal.jpg",
"profile_banner_url":"https://pbs.twimg.com/profile_banners/908704166595395585/1608340497",
"profile_image_extensions_alt_text":null,
"profile_banner_extensions_alt_text":null,
"profile_link_color":"E81C4F",
"profile_sidebar_border_color":"000000",
"profile_sidebar_fill_color":"000000",
"profile_text_color":"000000",
"profile_use_background_image":false,
"has_extended_profile":false,
"default_profile":false,
"default_profile_image":false,
"following":false,
"follow_request_sent":false,
"notifications":false,
"translator_type":"none"
},
"geo":null,
"coordinates":null,
"place":null,
"contributors":null,
"is_quote_status":true,
"quoted_status_id":1152001977355603968,
"quoted_status_id_str":"1152001977355603968",
"quoted_status_permalink":{
"url":"https://t.co/CWYOMCEpLu",
"expanded":"https://twitter.com/perlalessandra/status/1152001977355603968",
"display":"twitter.com/perlalessandra\u2026"
},
"quoted_status":{
"created_at":"Thu Jul 18 23:47:29 +0000 2019",
"id":1152001977355603968,
"id_str":"1152001977355603968",
"full_text":". @DJLUIAN pide en Premios Juventud la renuncia de Ricardo Rossell\u00f3 https://t.co/6iqdPl70D2",
"truncated":false,
"display_text_range":[
0,
67
],
"entities":{
"hashtags":[
],
"symbols":[
],
"user_mentions":[
{
"screen_name":"DJLUIAN",
"name":"HEAR THIS MUSIC",
"id":173607931,
"id_str":"173607931",
"indices":[
2,
10
]
}
],
"urls":[
],
"media":[
{
"id":1152001927623761923,
"id_str":"1152001927623761923",
"indices":[
68,
91
],
"media_url":"http://pbs.twimg.com/ext_tw_video_thumb/1152001927623761923/pu/img/lnW94uRsrZkMRMkQ.jpg",
"media_url_https":"https://pbs.twimg.com/ext_tw_video_thumb/1152001927623761923/pu/img/lnW94uRsrZkMRMkQ.jpg",
"url":"https://t.co/6iqdPl70D2",
"display_url":"pic.twitter.com/6iqdPl70D2",
"expanded_url":"https://twitter.com/perlalessandra/status/1152001977355603968/video/1",
"type":"photo",
"sizes":{
"thumb":{
"w":150,
"h":150,
"resize":"crop"
},
"medium":{
"w":1200,
"h":675,
"resize":"fit"
},
"small":{
"w":680,
"h":383,
"resize":"fit"
},
"large":{
"w":1280,
"h":720,
"resize":"fit"
}
}
}
]
},
"extended_entities":{
"media":[
{
"id":1152001927623761923,
"id_str":"1152001927623761923",
"indices":[
68,
91
],
"media_url":"http://pbs.twimg.com/ext_tw_video_thumb/1152001927623761923/pu/img/lnW94uRsrZkMRMkQ.jpg",
"media_url_https":"https://pbs.twimg.com/ext_tw_video_thumb/1152001927623761923/pu/img/lnW94uRsrZkMRMkQ.jpg",
"url":"https://t.co/6iqdPl70D2",
"display_url":"pic.twitter.com/6iqdPl70D2",
"expanded_url":"https://twitter.com/perlalessandra/status/1152001977355603968/video/1",
"type":"video",
"sizes":{
"thumb":{
"w":150,
"h":150,
"resize":"crop"
},
"medium":{
"w":1200,
"h":675,
"resize":"fit"
},
"small":{
"w":680,
"h":383,
"resize":"fit"
},
"large":{
"w":1280,
"h":720,
"resize":"fit"
}
},
"video_info":{
"aspect_ratio":[
16,
9
],
"duration_millis":5670,
"variants":[
{
"content_type":"application/x-mpegURL",
"url":"https://video.twimg.com/ext_tw_video/1152001927623761923/pu/pl/qQoayzm6EBar1f9M.m3u8?tag=10"
},
{
"bitrate":832000,
"content_type":"video/mp4",
"url":"https://video.twimg.com/ext_tw_video/1152001927623761923/pu/vid/640x360/scZWK1m35HHcj-of.mp4?tag=10"
},
{
"bitrate":256000,
"content_type":"video/mp4",
"url":"https://video.twimg.com/ext_tw_video/1152001927623761923/pu/vid/480x270/kyrUdfQzf6vrHTML.mp4?tag=10"
},
{
"bitrate":2176000,
"content_type":"video/mp4",
"url":"https://video.twimg.com/ext_tw_video/1152001927623761923/pu/vid/1280x720/CAwW5g8sM9qqdbqP.mp4?tag=10"
}
]
},
"ext_alt_text":null,
"additional_media_info":{
"monetizable":false
}
}
]
},
"source":"Twitter for iPhone",
"in_reply_to_status_id":null,
"in_reply_to_status_id_str":null,
"in_reply_to_user_id":null,
"in_reply_to_user_id_str":null,
"in_reply_to_screen_name":null,
"user":{
"id":2907223512,
"id_str":"2907223512",
"name":"Perla Alessandra",
"screen_name":"perlalessandra",
"location":"Puerto Rico",
"description":"Una periodista juzgada por sus tuits. Fitness trainer | #NiUnaMenos",
"url":null,
"entities":{
"description":{
"urls":[
]
}
},
"protected":false,
"followers_count":1473,
"friends_count":849,
"listed_count":16,
"created_at":"Sat Nov 22 14:42:58 +0000 2014",
"favourites_count":583,
"utc_offset":null,
"time_zone":null,
"geo_enabled":true,
"verified":false,
"statuses_count":25533,
"lang":null,
"contributors_enabled":false,
"is_translator":false,
"is_translation_enabled":false,
"profile_background_color":"000000",
"profile_background_image_url":"http://abs.twimg.com/images/themes/theme1/bg.png",
"profile_background_image_url_https":"https://abs.twimg.com/images/themes/theme1/bg.png",
"profile_background_tile":false,
"profile_image_url":"http://pbs.twimg.com/profile_images/1374119633452683295/ypyGZO_I_normal.jpg",
"profile_image_url_https":"https://pbs.twimg.com/profile_images/1374119633452683295/ypyGZO_I_normal.jpg",
"profile_banner_url":"https://pbs.twimg.com/profile_banners/2907223512/1610062269",
"profile_image_extensions_alt_text":null,
"profile_banner_extensions_alt_text":null,
"profile_link_color":"981CEB",
"profile_sidebar_border_color":"000000",
"profile_sidebar_fill_color":"000000",
"profile_text_color":"000000",
"profile_use_background_image":false,
"has_extended_profile":true,
"default_profile":false,
"default_profile_image":false,
"following":false,
"follow_request_sent":false,
"notifications":false,
"translator_type":"none"
},
"geo":null,
"coordinates":null,
"place":null,
"contributors":null,
"is_quote_status":false,
"retweet_count":911,
"favorite_count":1555,
"favorited":false,
"retweeted":false,
"possibly_sensitive":false,
"lang":"es"
},
"retweet_count":1392,
"favorite_count":1856,
"favorited":false,
"retweeted":false,
"possibly_sensitive":false,
"lang":"es"
},
"is_quote_status":true,
"quoted_status_id":1152001977355603968,
"quoted_status_id_str":"1152001977355603968",
"quoted_status_permalink":{
"url":"https://t.co/CWYOMCEpLu",
"expanded":"https://twitter.com/perlalessandra/status/1152001977355603968",
"display":"twitter.com/perlalessandra\u2026"
},
"retweet_count":1392,
"favorite_count":0,
"favorited":false,
"retweeted":false,
"possibly_sensitive":false,
"lang":"es"
}
For more information about Twitter API structure and data dictionaries you can visit: https://developer.twitter.com/en/docs/twitter-api/v1/data-dictionary/overview
RDF in context with Schema.org¶
The SocialMediaPosting at Schema.org offers a Resource Description Framework schema that is complatible with multiple social media platforms including Facebook and Twitter. This schema should work for long term preservation and allow cross platform data analysis for researchers. RDF schemas are also useful to standardize metadata fields and relationships before archiving content for posterity.
This is an example of how we can visualize RDF graphs for a single tweet from the #RickyRenuncia dataset.

Graph generated by: https://rdfa.info/play/
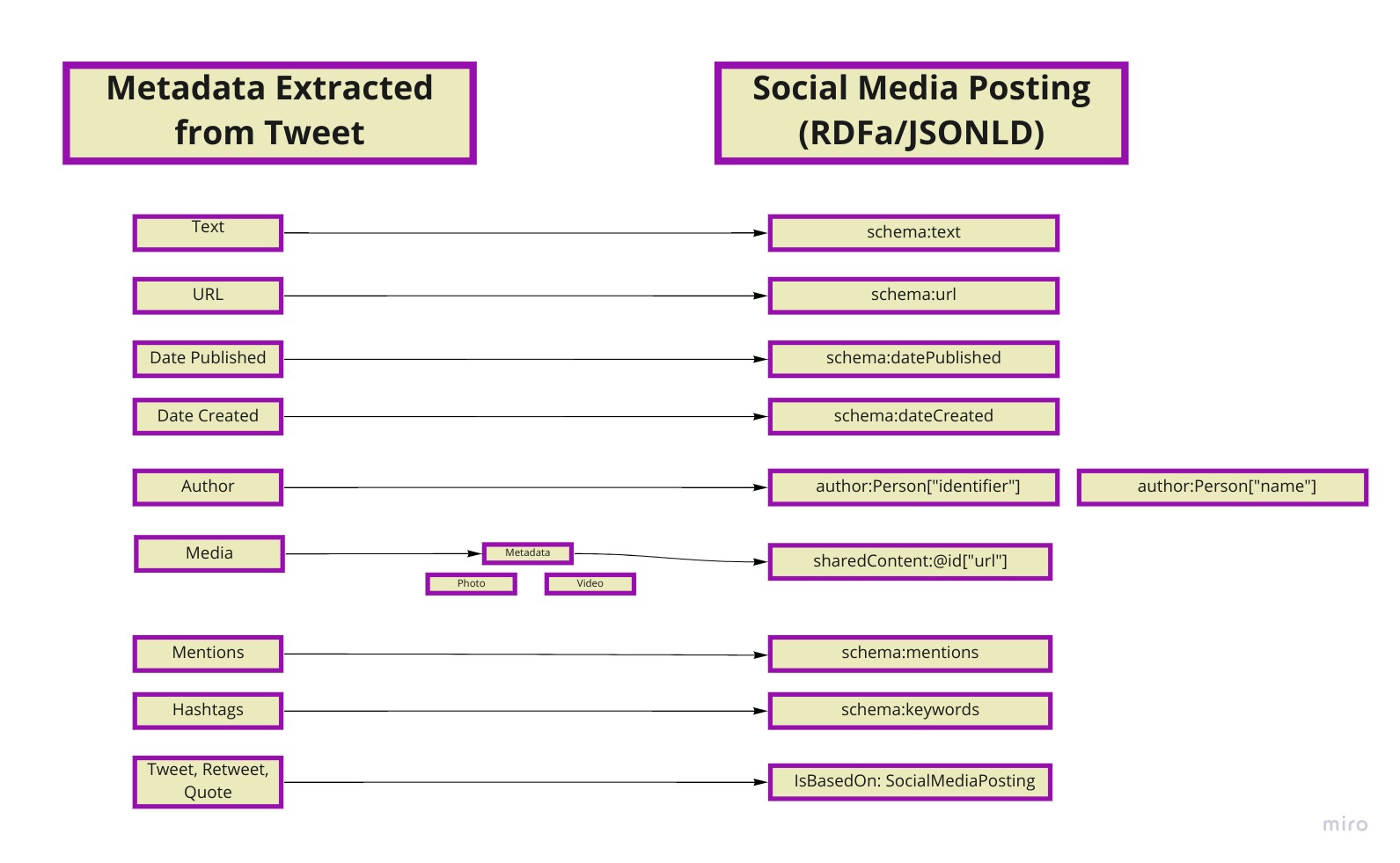
Metadata Design¶
The metadata vocabularies used in this project are extracted from Schema.org. By complementing the Social Media Posting, Creative Work and Media Object templates the project was able to successfully create relations between Original Tweets, Retweets, Quoted Retweets and its shared media.
An important metadata field used to allow this relation is the isBasedOn from Schema.org. The isBasedOn field is used to represent "A resource from which this work is derived or from which it is a modification or adaption" (from Schema.org Website). It accepts as a digital object a URL or an Item derived from a Creative Work template.
The Resource templates created for this project attempt to preserve relevant information of the Tweet object.
For this project, the relevant information is:
- User identifier
- User Tweet Handle
- Date of the Tweet
- Text of the tweet
- Hashtags
- Other Twitter User Mentions
- Tweet Media
- If is based out of other tweet or not
- Date Retrieved
- Date Accessed
Download Data¶
A sample data set of 500 tweets is available from the team website https://libarchivist.com/rrp/rickyrenuncia/sample_500.jsonl.
The next code uses the requests library to download the file and store it in a local file.
import requests
from os.path import isfile
data_url = "https://libarchivist.com/rrp/rickyrenuncia/sample_500.jsonl"
local_file = "rrhydrated.jsonl"
# If file has not been downloaded previously -> Download it.
if not isfile(local_file):
response = requests.get(data_url, allow_redirects=True)
with open(local_file, "wb") as handler:
handler.write(response.content)
print(f"Downloaded into '{local_file}'.")
else:
print(f"Data in '{local_file}'.")
Install Tweet-Requester package¶
The tweet-requester (GitHub - PyPI) library was developed by the team to request data from the Twitter API.
# Install a pip package in the current Jupyter kernel
import sys
!{sys.executable} -m pip install -q tweet-requester
!{sys.executable} -m pip show tweet-requester
Import Python Libraries¶
Thetyping library objects List and Union allow hinting types used and returned by fuctions.
The JSON library is used to import the Twitter data dictionaries.
As part of our Tweet Rehydrate library, we developed an object called TweetAnalyzer that can extract multiple metadata fields from a Twitter API v1.1 and is used to construct JSON-LD and RDFa output.
from typing import List, Union
import json
from tweet_requester.analysis import TweetAnalyzer, TweetMedia
from tweet_requester.display import wrapCodeIPython
Now that the libraries are imported, we can start coding.
Generate RDFa¶
Utilize an RDFa metadata template tp generate a HTML code correctly mapping the metadata.
# This is a function that creates the RDFa metadata template.
# It pairs fields from a Twitter JSONL using the TweetRequester Python library.
def create_tweet_rdfa(tweet: Union[dict, TweetAnalyzer]):
if type(tweet) is not TweetAnalyzer:
tweet = TweetAnalyzer(tweet)
media_rdfa=""
for media in tweet.media:
media_rdfa_template=f"""
<p property="sharedContent" typeof="MediaObject">
View Media:
<a property="identifier" href="{media.url()}" target="_blank">
{media.id}
</a> -
<span property="encodingFormat">{media.mtype()}</span>
<p>
"""
media_rdfa += media_rdfa_template
hashtags= [
f'<li property="keywords" typeof="DefinedTerm"><span property="name">#{hashtag["text"]}</span></li>' for hashtag in tweet.data["entities"]["hashtags"]
]
hashtag_rdfa= f'<div>Hashtags:<ul>{" ".join(hashtags)}</ul></div>'
is_based_on = ""
if tweet.isRetweet:
is_based_on += f"""
<p>Retweet of:
<span property="isBasedOn" typeof="SocialMediaPosting">
<a property="identifier" href="{tweet.retweeted_status.urlByIDs()}" target="_blank">{tweet.retweeted_status.text()[:30]}</a>
</span>
</p>
"""
elif tweet.isQuote:
is_based_on += f"""
<p>Quoted:
<span property="isBasedOn" typeof="SocialMediaPosting">
<a property="identifier" href="{tweet.quoted_status.urlByIDs()}">{tweet.quoted_status.text()[:30]}</a>
</span>
</p>
"""
date_data_rehydrated = "2021-03-26"
rdfa = f"""
<div vocab="https://schema.org/" typeof="SocialMediaPosting" resource="{tweet.urlByIDs()}">
<p property="text">{tweet.text()}</p>
<a property="url" href="{tweet.url()}">Visit Tweet</a></span>
<p>Date Published: <span property="datePublished">{tweet.data["created_at"]}</span></p>
<p>Accessed Date: <span property="dateCreated">{date_data_rehydrated}</span></p>
<p>Author:
<span property="author" typeof="Person">
<span property="name"><a property="identifier" href="https://twitter.com/{tweet.user_screen_name}" target="_blank">{tweet.user_screen_name}</a><meta property="identifier" content="{tweet.user_id}"></meta></span>
</span>
</p>
{media_rdfa}
{hashtag_rdfa}
{is_based_on}
</div>
"""
return rdfa
Now that the template is set up and the crosswalk between the Twitter JSONL dataset and RDFA is done, we can visualize it.
Visualize RDFa¶
Load sample tweet
json_str = ""
with open("./rrhydrated.jsonl", "r") as data_handler:
data_handler.readline()
json_str = data_handler.readline()
# print(json_str)
tweet = TweetAnalyzer(json_str)
rdfa = create_tweet_rdfa(tweet)
This is the raw version of a tweet converted to HTML/RDFa.
print(rdfa)
This is a the actual display of HTML/RDFa rendered without CSS styling.
from IPython.core.display import display, HTML
display(HTML(rdfa))
JSON-LD Metadata Crosswalk¶
Utilize an JSON-LD metadata template to generate a HTML code correctly mapping the metadata.
# This is a function that creates the JSON-LD metadata template.
# It pairs fields from a Twitter JSONL using the TweetRequester Python library.
def create_tweet_jsonld(tweet: Union[dict, TweetAnalyzer]):
if type(tweet) is not TweetAnalyzer:
tweet = TweetAnalyzer(tweet)
tweet._hasLocalMedia()
all_media = []
for media in tweet.media:
all_media.append({
"@type":[
"schema:MediaObject",
],
"schema:identifier": [
{
"type": "literal",
"property_label": "identifier",
"@value": media.url()
},
],
"schema:encodingFormat":{
"type": "literal",
"property_label": "encodingFormat",
"@value": media.mtype()
}
})
date_data_rehydrated = "2021-03-26"
# schema: points to Schema.org metadata
data = {
"@context": {
"schema": "https://schema.org/"
},
"@type": [
"schema:SocialMediaPosting",
],
# "schema:isBasedOn": isBasedOn,
"schema:identifier": [
{
"type": "literal",
"property_label": "identifier",
# "is_public": true,
"@value": tweet.urlByIDs()
}
],
"schema:url": [
{
"type": "literal",
"property_label": "url",
# "is_public": true,
"@value": tweet.url()
}
],
"schema:datePublished": [
{
"type": "literal",
"property_label": "datePublished",
# "is_public": true,
"@value": tweet.data["created_at"]
}
],
"schema:dateCreated": [
{
"type": "literal",
"property_label": "dateCreated",
# "is_public": true,
"@value": date_data_rehydrated
}
],
"schema:author": [
{
"@type": "schema:Person",
"schema:identifier": [
f"https://twitter.com/{tweet.user_screen_name}",
tweet.user_id,
],
"schema:name": {
"type": "literal",
"@value": tweet.user_screen_name
},
}
],
"schema:text": [
{
"type": "literal",
"property_label": "text",
# "is_public": true,
"@value": tweet.data["full_text"]
}
],
"schema:sharedContent": all_media,
"schema:mentions": [
{
"type": "literal",
"property_label": "mentions",
# "is_public": true,
"@value": uMention["screen_name"]
}
for uMention in tweet.data["entities"]["user_mentions"]
],
"schema:keywords": [
{
"type": "literal",
"property_label": "keywords",
# "is_public": true,
"@value": "#"+hashtag["text"]
} for hashtag in tweet.data["entities"]["hashtags"]
],
}
if tweet.isRetweet:
isBasedOn = {
"type": "SocialMediaPosting",
"schema:identifier": tweet.retweeted_status.urlByIDs(),
}
data["schema:isBasedOn"] = isBasedOn
elif tweet.isQuote:
isBasedOn = {
"type": "SocialMediaPosting",
"schema:identifier": tweet.quoted_status.urlByIDs(),
}
data["schema:isBasedOn"] = isBasedOn
return data
Now that the template is set up and the crosswalk between the Twitter JSONL dataset and JSONLD is done, we can visualize it.
Visualize JSON-LD¶
Load sample tweet
json_str = ""
with open("./rrhydrated.jsonl", "r") as data_handler:
json_str = data_handler.readline()
tweet = TweetAnalyzer(json_str)
json_ld = create_tweet_jsonld(tweet)
This is how looks a JSONLD data structure
jdump = json.dumps(json_ld, indent=3)
wrapCodeIPython(jdump, size=0.85, lines=35)
Discussion¶
Data Structures, RDFa & JSON-LD¶
Take a moment to reflect on the purpose and structure of each data schema. Think of the visual diferences that both metadata structures have. RDFA can allow you to have a CSS styled representation of the data. JSON-LD can allow you to transfer data using API's.
Exercises¶
Add a metadata field to the RDFa and JSON-LD templates.¶
Study the Twitter data schema and pair one of them with a Schema.org metadata field.
Use the Schema.org website to research the available metadata fields,https://schema.org/.
Also, you can use this Twitter JSON as an example to perform the crosswalk.
Below there is an example of how Twitter data is being pulled from their API in an JSON format.
{
"created_at":"Fri Jul 19 00:31:42 +0000 2019",
"id":1152013106656079872,
"id_str":"1152013106656079872",
"full_text":"RT @ninofray: No vamos a vacilarle los fake abs por un a\u00f1o. #RickyRenuncia #RickyDictador https://t.co/CWYOMCEpLu",
"truncated":false,
"display_text_range":[
0,
113
],
"entities":{
"hashtags":[
{
"text":"RickyRenuncia",
"indices":[
60,
74
]
},
{
"text":"RickyDictador",
"indices":[
75,
89
]
}
],
"symbols":[
],
"user_mentions":[
{
"screen_name":"ninofray",
"name":"n i n o",
"id":908704166595395585,
"id_str":"908704166595395585",
"indices":[
3,
12
]
}
],
"urls":[
{
"url":"https://t.co/CWYOMCEpLu",
"expanded_url":"https://twitter.com/perlalessandra/status/1152001977355603968",
"display_url":"twitter.com/perlalessandra\u2026",
"indices":[
90,
113
]
}
]
},
"source":"Twitter for iPhone",
"in_reply_to_status_id":null,
"in_reply_to_status_id_str":null,
"in_reply_to_user_id":null,
"in_reply_to_user_id_str":null,
"in_reply_to_screen_name":null,
"user":{
"id":890123263,
"id_str":"890123263",
"name":"Edgar \u26bd\ufe0f",
"screen_name":"Junfcb00",
"location":"",
"description":"UPRM SC:junfcb00",
"url":null,
"entities":{
"description":{
"urls":[
]
}
},
"protected":false,
"followers_count":327,
"friends_count":284,
"listed_count":1,
"created_at":"Fri Oct 19 01:59:11 +0000 2012",
"favourites_count":111913,
"utc_offset":null,
"time_zone":null,
"geo_enabled":true,
"verified":false,
"statuses_count":46558,
"lang":null,
"contributors_enabled":false,
"is_translator":false,
"is_translation_enabled":false,
"profile_background_color":"C0DEED",
"profile_background_image_url":"http://abs.twimg.com/images/themes/theme1/bg.png",
"profile_background_image_url_https":"https://abs.twimg.com/images/themes/theme1/bg.png",
"profile_background_tile":false,
"profile_image_url":"http://pbs.twimg.com/profile_images/1249111605612142593/eBzfrEj8_normal.jpg",
"profile_image_url_https":"https://pbs.twimg.com/profile_images/1249111605612142593/eBzfrEj8_normal.jpg",
"profile_banner_url":"https://pbs.twimg.com/profile_banners/890123263/1561030388",
"profile_image_extensions_alt_text":null,
"profile_banner_extensions_alt_text":null,
"profile_link_color":"1DA1F2",
"profile_sidebar_border_color":"C0DEED",
"profile_sidebar_fill_color":"DDEEF6",
"profile_text_color":"333333",
"profile_use_background_image":true,
"has_extended_profile":false,
"default_profile":true,
"default_profile_image":false,
"following":false,
"follow_request_sent":false,
"notifications":false,
"translator_type":"none"
},
"geo":null,
"coordinates":null,
"place":null,
"contributors":null,
"retweeted_status":{
"created_at":"Thu Jul 18 23:48:37 +0000 2019",
"id":1152002265080725504,
"id_str":"1152002265080725504",
"full_text":"No vamos a vacilarle los fake abs por un a\u00f1o. #RickyRenuncia #RickyDictador https://t.co/CWYOMCEpLu",
"truncated":false,
"display_text_range":[
0,
75
],
"entities":{
"hashtags":[
{
"text":"RickyRenuncia",
"indices":[
46,
60
]
},
{
"text":"RickyDictador",
"indices":[
61,
75
]
}
],
"symbols":[
],
"user_mentions":[
],
"urls":[
{
"url":"https://t.co/CWYOMCEpLu",
"expanded_url":"https://twitter.com/perlalessandra/status/1152001977355603968",
"display_url":"twitter.com/perlalessandra\u2026",
"indices":[
76,
99
]
}
]
},
"source":"Twitter for iPhone",
"in_reply_to_status_id":null,
"in_reply_to_status_id_str":null,
"in_reply_to_user_id":null,
"in_reply_to_user_id_str":null,
"in_reply_to_screen_name":null,
"user":{
"id":908704166595395585,
"id_str":"908704166595395585",
"name":"n i n o",
"screen_name":"ninofray",
"location":"",
"description":"this is the way",
"url":null,
"entities":{
"description":{
"urls":[
]
}
},
"protected":false,
"followers_count":260,
"friends_count":449,
"listed_count":0,
"created_at":"Fri Sep 15 14:48:51 +0000 2017",
"favourites_count":485,
"utc_offset":null,
"time_zone":null,
"geo_enabled":true,
"verified":false,
"statuses_count":1836,
"lang":null,
"contributors_enabled":false,
"is_translator":false,
"is_translation_enabled":false,
"profile_background_color":"000000",
"profile_background_image_url":"http://abs.twimg.com/images/themes/theme1/bg.png",
"profile_background_image_url_https":"https://abs.twimg.com/images/themes/theme1/bg.png",
"profile_background_tile":false,
"profile_image_url":"http://pbs.twimg.com/profile_images/1327750989290430466/01EOtvlZ_normal.jpg",
"profile_image_url_https":"https://pbs.twimg.com/profile_images/1327750989290430466/01EOtvlZ_normal.jpg",
"profile_banner_url":"https://pbs.twimg.com/profile_banners/908704166595395585/1608340497",
"profile_image_extensions_alt_text":null,
"profile_banner_extensions_alt_text":null,
"profile_link_color":"E81C4F",
"profile_sidebar_border_color":"000000",
"profile_sidebar_fill_color":"000000",
"profile_text_color":"000000",
"profile_use_background_image":false,
"has_extended_profile":false,
"default_profile":false,
"default_profile_image":false,
"following":false,
"follow_request_sent":false,
"notifications":false,
"translator_type":"none"
},
"geo":null,
"coordinates":null,
"place":null,
"contributors":null,
"is_quote_status":true,
"quoted_status_id":1152001977355603968,
"quoted_status_id_str":"1152001977355603968",
"quoted_status_permalink":{
"url":"https://t.co/CWYOMCEpLu",
"expanded":"https://twitter.com/perlalessandra/status/1152001977355603968",
"display":"twitter.com/perlalessandra\u2026"
},
"quoted_status":{
"created_at":"Thu Jul 18 23:47:29 +0000 2019",
"id":1152001977355603968,
"id_str":"1152001977355603968",
"full_text":". @DJLUIAN pide en Premios Juventud la renuncia de Ricardo Rossell\u00f3 https://t.co/6iqdPl70D2",
"truncated":false,
"display_text_range":[
0,
67
],
"entities":{
"hashtags":[
],
"symbols":[
],
"user_mentions":[
{
"screen_name":"DJLUIAN",
"name":"HEAR THIS MUSIC",
"id":173607931,
"id_str":"173607931",
"indices":[
2,
10
]
}
],
"urls":[
],
"media":[
{
"id":1152001927623761923,
"id_str":"1152001927623761923",
"indices":[
68,
91
],
"media_url":"http://pbs.twimg.com/ext_tw_video_thumb/1152001927623761923/pu/img/lnW94uRsrZkMRMkQ.jpg",
"media_url_https":"https://pbs.twimg.com/ext_tw_video_thumb/1152001927623761923/pu/img/lnW94uRsrZkMRMkQ.jpg",
"url":"https://t.co/6iqdPl70D2",
"display_url":"pic.twitter.com/6iqdPl70D2",
"expanded_url":"https://twitter.com/perlalessandra/status/1152001977355603968/video/1",
"type":"photo",
"sizes":{
"thumb":{
"w":150,
"h":150,
"resize":"crop"
},
"medium":{
"w":1200,
"h":675,
"resize":"fit"
},
"small":{
"w":680,
"h":383,
"resize":"fit"
},
"large":{
"w":1280,
"h":720,
"resize":"fit"
}
}
}
]
},
"extended_entities":{
"media":[
{
"id":1152001927623761923,
"id_str":"1152001927623761923",
"indices":[
68,
91
],
"media_url":"http://pbs.twimg.com/ext_tw_video_thumb/1152001927623761923/pu/img/lnW94uRsrZkMRMkQ.jpg",
"media_url_https":"https://pbs.twimg.com/ext_tw_video_thumb/1152001927623761923/pu/img/lnW94uRsrZkMRMkQ.jpg",
"url":"https://t.co/6iqdPl70D2",
"display_url":"pic.twitter.com/6iqdPl70D2",
"expanded_url":"https://twitter.com/perlalessandra/status/1152001977355603968/video/1",
"type":"video",
"sizes":{
"thumb":{
"w":150,
"h":150,
"resize":"crop"
},
"medium":{
"w":1200,
"h":675,
"resize":"fit"
},
"small":{
"w":680,
"h":383,
"resize":"fit"
},
"large":{
"w":1280,
"h":720,
"resize":"fit"
}
},
"video_info":{
"aspect_ratio":[
16,
9
],
"duration_millis":5670,
"variants":[
{
"content_type":"application/x-mpegURL",
"url":"https://video.twimg.com/ext_tw_video/1152001927623761923/pu/pl/qQoayzm6EBar1f9M.m3u8?tag=10"
},
{
"bitrate":832000,
"content_type":"video/mp4",
"url":"https://video.twimg.com/ext_tw_video/1152001927623761923/pu/vid/640x360/scZWK1m35HHcj-of.mp4?tag=10"
},
{
"bitrate":256000,
"content_type":"video/mp4",
"url":"https://video.twimg.com/ext_tw_video/1152001927623761923/pu/vid/480x270/kyrUdfQzf6vrHTML.mp4?tag=10"
},
{
"bitrate":2176000,
"content_type":"video/mp4",
"url":"https://video.twimg.com/ext_tw_video/1152001927623761923/pu/vid/1280x720/CAwW5g8sM9qqdbqP.mp4?tag=10"
}
]
},
"ext_alt_text":null,
"additional_media_info":{
"monetizable":false
}
}
]
},
"source":"Twitter for iPhone",
"in_reply_to_status_id":null,
"in_reply_to_status_id_str":null,
"in_reply_to_user_id":null,
"in_reply_to_user_id_str":null,
"in_reply_to_screen_name":null,
"user":{
"id":2907223512,
"id_str":"2907223512",
"name":"Perla Alessandra",
"screen_name":"perlalessandra",
"location":"Puerto Rico",
"description":"Una periodista juzgada por sus tuits. Fitness trainer | #NiUnaMenos",
"url":null,
"entities":{
"description":{
"urls":[
]
}
},
"protected":false,
"followers_count":1473,
"friends_count":849,
"listed_count":16,
"created_at":"Sat Nov 22 14:42:58 +0000 2014",
"favourites_count":583,
"utc_offset":null,
"time_zone":null,
"geo_enabled":true,
"verified":false,
"statuses_count":25533,
"lang":null,
"contributors_enabled":false,
"is_translator":false,
"is_translation_enabled":false,
"profile_background_color":"000000",
"profile_background_image_url":"http://abs.twimg.com/images/themes/theme1/bg.png",
"profile_background_image_url_https":"https://abs.twimg.com/images/themes/theme1/bg.png",
"profile_background_tile":false,
"profile_image_url":"http://pbs.twimg.com/profile_images/1374119633452683295/ypyGZO_I_normal.jpg",
"profile_image_url_https":"https://pbs.twimg.com/profile_images/1374119633452683295/ypyGZO_I_normal.jpg",
"profile_banner_url":"https://pbs.twimg.com/profile_banners/2907223512/1610062269",
"profile_image_extensions_alt_text":null,
"profile_banner_extensions_alt_text":null,
"profile_link_color":"981CEB",
"profile_sidebar_border_color":"000000",
"profile_sidebar_fill_color":"000000",
"profile_text_color":"000000",
"profile_use_background_image":false,
"has_extended_profile":true,
"default_profile":false,
"default_profile_image":false,
"following":false,
"follow_request_sent":false,
"notifications":false,
"translator_type":"none"
},
"geo":null,
"coordinates":null,
"place":null,
"contributors":null,
"is_quote_status":false,
"retweet_count":911,
"favorite_count":1555,
"favorited":false,
"retweeted":false,
"possibly_sensitive":false,
"lang":"es"
},
"retweet_count":1392,
"favorite_count":1856,
"favorited":false,
"retweeted":false,
"possibly_sensitive":false,
"lang":"es"
},
"is_quote_status":true,
"quoted_status_id":1152001977355603968,
"quoted_status_id_str":"1152001977355603968",
"quoted_status_permalink":{
"url":"https://t.co/CWYOMCEpLu",
"expanded":"https://twitter.com/perlalessandra/status/1152001977355603968",
"display":"twitter.com/perlalessandra\u2026"
},
"retweet_count":1392,
"favorite_count":0,
"favorited":false,
"retweeted":false,
"possibly_sensitive":false,
"lang":"es"
}
Test your RDFa and JSON-LD outputs by using a validator¶
W3c Schools provides a RDfa validator which can help you find if you are structuring appropiately your RDF. https://www.w3.org/2012/pyRdfa/Validator.html#distill_by_input
The JSON-LD website can provide you input on how you are structuring your JSON-LD. https://json-ld.org/playground/
What's next?¶
Continue to Twarc Tutorial to continue with the experience.